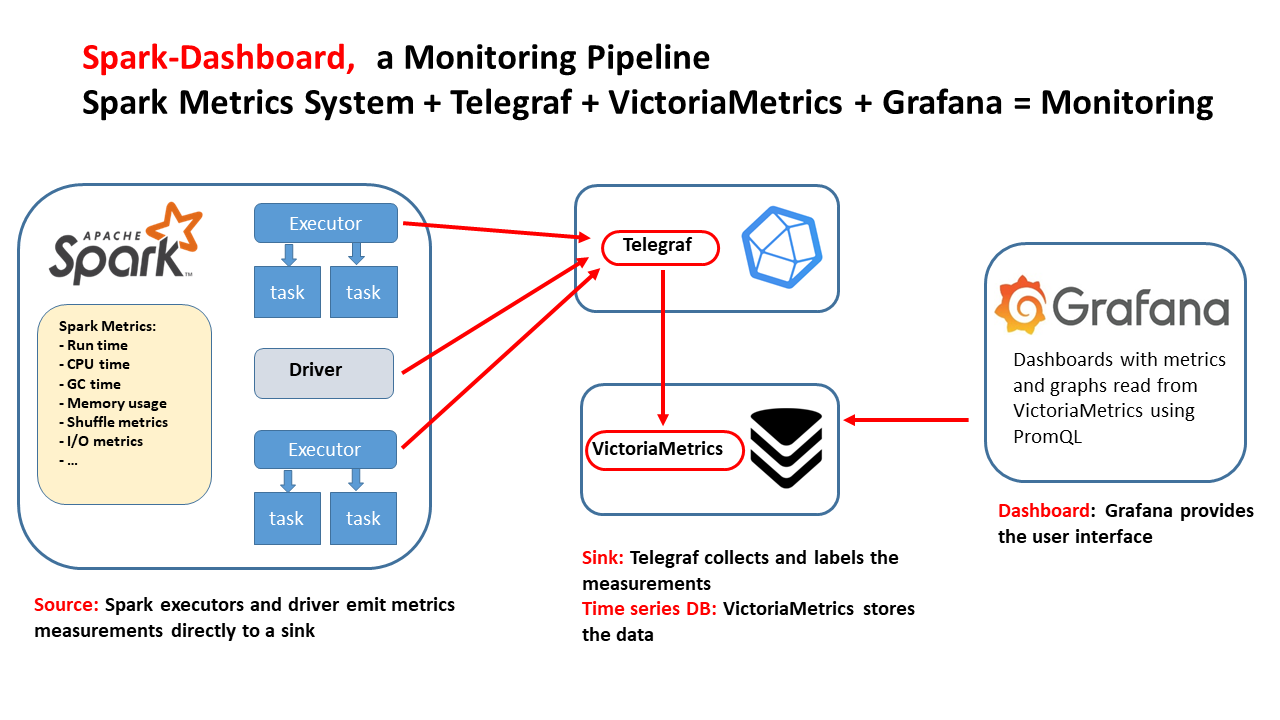
🚀 Quickly measure and load-test your CPUs with a simple Rust tool: test_cpu_parallel
How fast is your CPU really, right now?
It sounds like a simple question, but in modern environments it rarely has a simple answer, and getting it wrong can cost you performance, money, and confidence in your systems.
Virtual machines, containers, cloud instances, power-management policies, and opaque hardware specifications all conspire to hide real CPU performance. Even machines that look identical on paper may behave very differently in practice. Traditional benchmarking suites can help, but they are often heavy, slow, and excessive when all you need is a quick, practical measurement.
In this post, I show how developers and system engineers can quickly sanity-check CPU performance across machines and spot throttling or oversubscription using a simple, practical tool:
test_cpu_parallel
====
Disclaimer
This post is not about precise CPU benchmarking or producing a single “CPU speed” number. Real workloads vary widely, compute-bound, memory-bound, or I/O-bound, and benchmarks that try to reduce this complexity to one figure can be misleading. This work is no exception.
Accordingly, we do not compare this approach with other benchmarking tools. The goal is a fast, lightweight diagnostic, not a replacement for rigorous, workload-specific benchmarking. For a deeper treatment of CPU performance analysis, see Performance Analysis and Tuning on Modern CPUs by Denis Bakhvalov:
https://github.com/dendibakh/perf-book
====
🛠 A simple way to measure CPU speed
test_cpu_parallel is a lightweight Rust tool that runs configurable CPU and memory workloads and gives you comparable performance numbers quickly.
It creates multiple worker threads and times how long they take to complete a fixed amount of CPU (or memory) work. Try it:
# Run with docker or podman:
docker run lucacanali/test_cpu_parallel /opt/test_cpu_parallel -w 2
This runs a synthetic CPU workload on 2 threads and returns the job completion time. You can directly compare these numbers across machines, architectures, or configurations.
📈 Compare performance across systems
(Old laptop vs new laptop, on-prem vs cloud, etc.)
How does the performance of your new laptop compare to the old one or to a cloud VM you are using? To test scalability or compare architectures:
./test_cpu_parallel --num_workers 8 --full -o results.csv
This collects performance test runs for 1 through 8 threads and saves the results to a CSV file.
The result can be used to analyze the performance and how it scales as you increase the number of parallel threads on the CPU. In particular the speedup curve (see Figure 1) is particularly useful to find the saturation point of your system.
- Does
performance scale linearly at low thread counts?
- Where
does it flatten?
- Does
hyperthreading help or hurt?
- Where
does CPU saturation occur?
I’ve used this to compare everything from small laptops to
128-core servers — and the curves quickly reveal when performance is real vs.
just advertised.

☁️ Benchmarking cloud CPUs you don’t control
Cloud environments hide a lot from you:
Which CPU model? How many real cores? Are you being throttled?
test_cpu_parallel gives you a black-box diagnostic:
- Measure
how performance scales with threads
- Check
if doubling threads halves execution time
- Detect
oversubscription or noisy neighbors
- Catch
“burstable CPU” limits or throttling
If the speedup curve flattens early, something’s not right, and now you know.
🔄 How many CPU cores can you really use?
Say the LInux command lscpu reports:
- 16
CPUs
- 8
physical + 8 hyperthreads
Does it mean you can scale up your CPU-intensive workload to 16x or 8x, or else? What does this actually mean for performance?
Measure and find out how much does your system scale by running:
./test_cpu_parallel --num_workers 16 --full
This is quite useful for:
- CI/CD
runners whose specs change unexpectedly
- Cloud
VMs with unclear provisioning
- Detecting
misconfigured containers or Kubernetes limits
- Creating reliable performance baselines
📊 Advanced: Plotting
Speedup Graphs
• Compare different generations of CPU architectures.• Profile performance saturation points.• Provide performance regression baselines over time.
Examples:
Q1: How fast are your CPUs, today?
Run this from CLI, it will run a test and measure the CPU speed:
# Run with docker or podman:
docker run lucacanali/test_cpu_parallel /opt/test_cpu_parallel -w 1 Alternative, download the binary and run locally (for Linux x64 see also this link):
wget https://sparkdltrigger.web.cern.ch/sparkdltrigger/test_cpu_parallel/test_cpu_parallel
chmod +x test_cpu_parallel
./test_cpu_parallel -w 1 Also available for Windows: find more details here.
The tool will run for about one minute, depending on your CPU speed, and run a compute-intensive loop using (only) one CPU thread (configured with the option -w 1) and report the execution time.
You can then compare the run time across multiple platforms and/or across different time of the day to see if there are variations.
Example of output value:
$ docker run lucacanali/test_cpu_parallel /opt/test_cpu_parallel -w 1
Use for testing and comparing CPU performance [-h, --help] for help
Starting a test with num_workers = 1, num_job_execution_loops = 3,
worker_inner_loop_size = 30000, full = false, output_file = ""
Scheduling job batch number 1
Scheduled running of 1 concurrent worker threads
Job 0 finished. Result, delta_time = 44.49 sec
Scheduling job batch number 2
Scheduled running of 1 concurrent worker threads
Job 0 finished. Result, delta_time = 44.47 sec
Scheduling job batch number 3
Scheduled running of 1 concurrent worker threads
Job 0 finished. Result, delta_time = 44.49 sec
CPU-intensive jobs using num_workers=1 finished.
Job runtime statistics:
Mean job runtime = 44.49 sec
Median job runtime = 44.49 sec
Standard deviation = 0.01 sec
More info with the options, features and limitations of the testing tool at: Test_CPU_parallel_Rust on Github
Q2: How many CPU cores can I use?
A key advantage of using Test_CPU_parallel_Rust is that it provides an easy way to test multi-core and multi-CPU systems.
For example if you have two or more cores available on your system you can run the tool with option -w 2 and the load will run on two concurrent threads. You expect to run in about the same time as with the load 1 example, if that's not the case, you probably don't have 2 cores available
# Run with docker or podman, configure the number of concurrently running threads with -w option
docker run lucacanali/test_cpu_parallel /opt/test_cpu_parallel -w 2 Bonus points: Keep increasing the load with the option -w to see when you reach saturation.
What can you discover? That the system reports to have N cores available but it is not the case, as possibly you have been given a mixture of "logical cores" (cores that come from CPU hyperthreading)
Run on Kubernetes, see also: Doc on how to run on K8S
# Run on a Kubernetes clusterkubectl run test-cpu-pod --image=lucacanali/test_cpu_parallel --restart=Never -- /opt/test_cpu_parallel -w 2
Q3: How scale up the CPU load to saturation
When testing with increasing CPU load we expect to reach saturation of the CPU utilization at one point. Test_cpu_parallel provides an easy way to run scale up CPU load, by running multiple CPU load tests with an increasing number of concurrent threads and measuring the time for each run. This can be used to measure when the CPUs reach saturation. Saturation is expected when the number of concurrent running threads gets close to the number of available CPU (physical) cores in the system.
# Full mode will test all the values of num_workers from 1 to the value set with --num_workerstest_cpu_parallel --full --num_workers 8This exercise described in the blog post CPU Load Testing Exercises: Tools and Analysis for Oracle Database Servers shows how to use test_cpu_parallel to compare the relative performance of different CPU types
Two key metrics to analyze the performance are:
- throughput analysis: how many jobs per minute can the server run as the load increases? and at saturation?
- speedup: how well does the system scale? when running 2 concurrent threads do I get twice the workload or is there some overhead? Scaling up when do I reach saturation?
Another interesting metric is the single-threaded speed, this is the CPU speed we get when the system is lightly loaded, which could be useful on a laptop or desktop for example, which on servers we would typically see systems highly loaded most of the time.
Lessons learned: The case of the large box
The case of testing a large server with 128 cores using test_cpu_parallel
The result show that the box throughput increases as the number of concurrent threads increases but reaches saturation much earlier than the expected value of 128. There can be various reasons for that, including the thermal dissipation causing CPU cores to throttle. The lesson is: don't make hypotheses on how your CPU can scale, just measure your CPU!

Conclusions
Modern CPUs, especially in cloud, containerized, and virtualized environments, rarely behave as their specifications alone would suggest. Core counts, clock speeds, and instance types describe potential capacity, but they don’t tell you how much performance you actually get once the system is under load
test_cpu_parallel is built around a simple principle: measure, don’t assume.
It’s not a full benchmarking suite, but a fast, practical tool to:
sanity-check effective CPU (and memory) performance,
-
observe how a system scales under parallel load,
-
detect early saturation, throttling, or resource misconfiguration,
-
compare machines, VMs, containers, or environments with minimal effort.
The key takeaway is straightforward: in shared or virtualized environments, CPU scaling assumptions often fail. Whether due to contention, throttling, or opaque provisioning, a quick measurement and a speedup curve help reveal the CPU performance you actually get, not just what was requested.
Link to the project's Github page
Related work: CPU Load Testing Exercises




 Watch sparkMeasure's getting started demo and tutorial
Watch sparkMeasure's getting started demo and tutorial