Apache Spark is renowned for its speed and efficiency in handling large-scale data processing. However, optimizing Spark to achieve maximum performance requires a precise understanding of its inner workings. This blog post will guide you through establishing a Spark Performance Lab with essential tools and techniques aimed at enhancing Spark performance through detailed metrics analysis.
Why a Spark Performance Lab
The purpose of a Spark Performance Lab isn't just to measure the elapsed time of your Spark jobs but to understand the underlying performance metrics deeply. By using these metrics, you can create models that explain what's happening within Spark's execution and identify areas for improvement. Here are some key reasons to set up a Spark Performance Lab:
- Hands-on learning and testing: A controlled lab setting allows for safer experimentation with Spark configurations and tuning and also experimenting and understanding the monitoring tools and Spark-generated metrics.
- Load and scale: Our lab uses a workload generator, running TPCDS queries. This is a well-known set of complex queries that is representative of OLAP workloads, and that can easily be scaled up for testing from GBs to 100s of TBs.
- Improving your toolkit: Having a toolbox is invaluable, however you need to practice and understand their output in a sandbox environment before moving to production.
- Get value from the Spark metric system: Instead of focusing solely on how long a job takes, use detailed metrics to understand the performance and spot inefficiencies.
Tools and Components
In our Spark Performance Lab, several key tools and components form the backbone of our testing and monitoring environment:
- Workload generator:
- We use a custom tool, TPCDS-PySpark, to generate a consistent set of queries (TPCDS benchmark), creating a reliable testing framework.
- Spark instrumentation:
- Spark’s built-in Web UI for initial metrics and job visualization.
- Custom tools:
- SparkMeasure: Use this for detailed performance metrics collection.
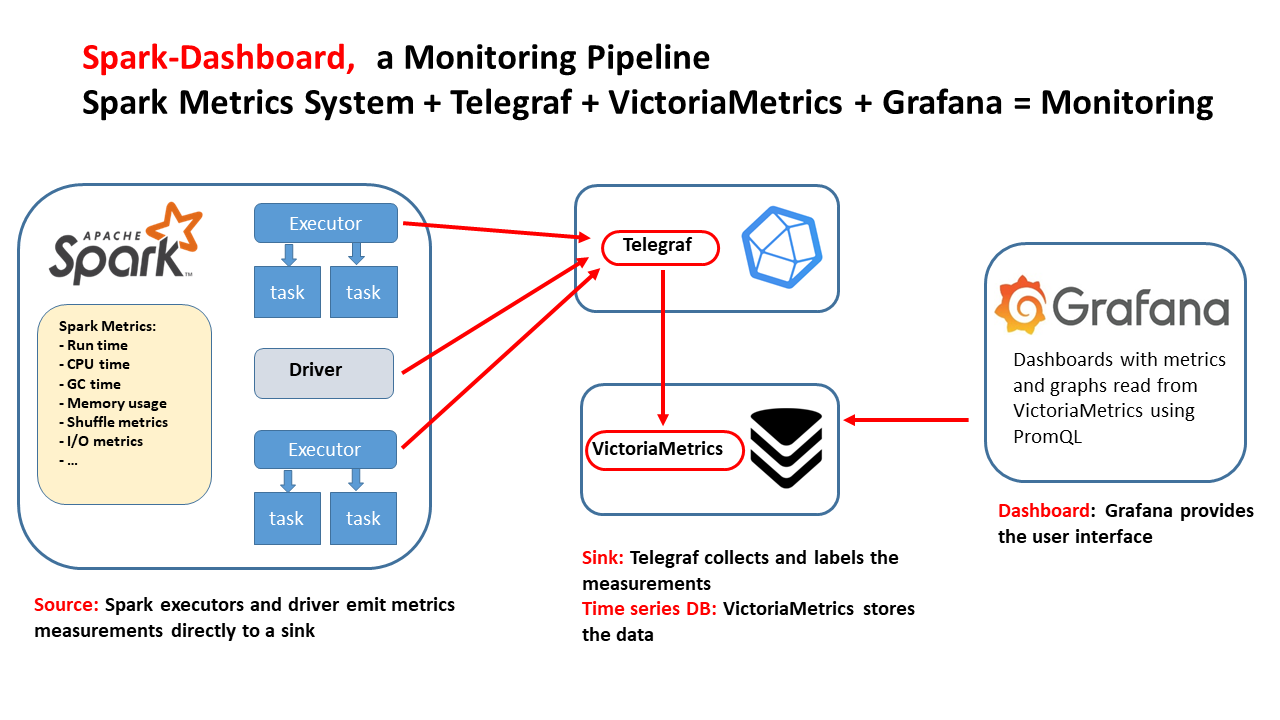
- Spark-Dashboard: Use this to monitor Spark jobs and visualize key performance metrics.
Demos
These quick demos and tutorials will show you how to use the tools in this Spark Performance Lab. You can follow along and get the same results on your own, which will help you start learning and exploring.- SparkMeasure - metrics collection
- TPCDS_PySpark - workload generator
- Spark-Dashboard - real-time dashboards
 Watch sparkMeasure's getting started demo and tutorial
Watch sparkMeasure's getting started demo and tutorial
How to Make the Best of Spark Metrics System
- Importance of Metrics: Metrics provide insights beyond simple timing, revealing details about task execution, resource utilization, and bottlenecks.
- Execution Time is Not Enough: Measuring the execution time of a job (how long it took to run it), is useful, but it doesn’t show the whole picture. Say the job ran in 10 seconds. It's crucial to understand why it took 10 seconds instead of 100 seconds or just 1 second. What was slowing things down? Was it the CPU, data input/output, or something else, like data shuffling? This helps us identify the root causes of performance issues.
- Key Metrics to Collect:
- Executor Run Time: Total time executors spend processing tasks.
- Executor CPU Time: Direct CPU time consumed by tasks.
- JVM GC Time: Time spent in garbage collection, affecting performance.
- Shuffle and I/O Metrics: Critical for understanding data movement and disk interactions.
- Memory Metrics: Key for performance and troubleshooting Out Of Memory errors.
- Metrics Analysis, what to look for:
- Look for bottlenecks: are there resources that are the bottleneck? Are the jobs running mostly on CPU or waiting for I/O or spending a lot of time on Garbage Collection?
- USE method: Utilization Saturation and Errors (USE) Method is a methodology for analyzing the performance of any system.
- The tools described here can help you to measure and understand Utilization and Saturation.
- Can your job use a significant fraction of the available CPU cores?
- Examine the measurement of the actual number of active tasks vs. time.
- Figure 1 shows the number of active tasks measured while running TPCDS 10TB on a YARN cluster, with 256 cores allocated. The graph shows spikes and troughs.
- Understand the root causes of the troughs using metrics and monitoring data. The reasons can be many: resource allocation, partition skew, straggler tasks, stage boundaries, etc.
- Which tool should I use?
- Start with using the Spark Web UI
- Instrument your jobs with sparkMesure. This is recommended early in the application development, testing, and for Continuous Integration (CI) pipelines.
- Observe your Spark application execution profile with Spark-Dashboard.
- Use available tools with OS metrics too. See also Spark-Dashboard extended instrumentation: it collects and visualizes OS metrics (from cgroup statistics) like network stats, etc
- Drill down:
- An example of Spark metrics analysis for TPCDS run at scale 10 TB
- Documentation:
- For those interested in delving deeper into Spark instrumentation and metrics, the Spark documentation offers a comprehensive guide.
- SparkMeasure: This tool captures metrics directly from Spark’s instrumentation via the Listener Bus. For a detailed understanding of how it operates, refer to the SparkMeasure architecture. It specifically gathers data from Spark's Task Metrics System, which you can explore further here.
- Spark-Dashboard: This application aggregates metrics that Spark exposes through the Dropwizard metrics library (see Spark-Dashboard architecture). A complete list of the metrics can be found here.
Lessons Learned and Conclusions
From setting up and running a Spark Performance Lab, here are some key takeaways:
- Collect, analyze and visualize metrics: Go beyond just measuring jobs' execution times to troubleshoot and fine-tune Spark performance effectively.
- Use the Right Tools: Familiarize yourself with tools for performance measurement and monitoring.
- Start Small, Scale Up: Begin with smaller datasets and configurations, then gradually scale to test larger, more complex scenarios.
- Tuning is an Iterative Process: Experiment with different configurations, parallelism levels, and data partitioning strategies to find the best setup for your workload.
Establishing a Spark Performance Lab is a fundamental step for any data engineer aiming to master Spark's performance aspects. By integrating tools like Web UI, TPCDS_PySpark, sparkMeasure, and Spark-Dashboard, developers and data engineers can gain unprecedented insights into Spark operations and optimizations.
Explore this lab setup to turn theory into expertise in managing and optimizing Apache Spark. Learn by doing and experimentation!
Acknowledgements: A special acknowledgment goes out to the teams behind the CERN data analytics, monitoring, and web notebook services, as well as the dedicated members of the ATLAS database group.