workloads in Apache Spark. You will find examples applied to studying a simple workload consisting of reading Apache Parquet files into a Spark DataFrame.
. Typical servers underlying current data platforms have a large and increasing amount of RAM and CPU cores compared to what was typically available just a few years ago. Moreover the widespread adoption of compressed columnar and/or in-memory data formats for data analytics further drives data platform to
This is mostly good news as CPU-bound workloads in many cases are easy to scale up (in particular for read-mostly workloads that don't require expensive serialization at the application/database engine level, like locks and latches).
in modern data processing platforms (people often refer to this as a "hitting a memory wall" or "RAM is the new disk") and one of the
that modern software for data processing has to handle is how to best utilize CPU cores, this often means implementing algorithms to minimize stalls due to
and utilizing memory bandwidth with vector processing (e.g. using SIMD instructions).
, make data processing at scale easier and cheaper. Techniques and
data processing workloads, including their CPU and memory footprint, are important to get the best
out of your software and hardware investment. If you are a software
your workloads. If you are working with
to you and know what to watch out for in case you have noisy neighbors in your shared/
environment. Either way you can find in this post a few examples and techniques that may help you in your job.
The work described here originates from a larger set of activities related to characterizing workloads of interest for sizing Spark clusters that the CERN Hadoop and Spark service team did in Q1 2017. In that context working with Spark and data files in columnar format, such as
is a key data format for high energy physics) is very important for many use cases from CERN users. Some of the first qualitative observations we noticed when running test workloads/benchmarks on Parquet tables were:
In this post I report on follow-up tests to drill down with measurements on some of the interesting details. The goal of the post is also to showcase
In the first part of this post you will find an example and a few drill-down lab tests on
CPU-intensive Spark workloads. You will see examples of profiling the workload of a query reading from Parquet by measuring systems resources utilization using Spark metrics and OS tools, including tools for stack profiling and
.
when it is executed in parallel by multiple executor threads. You will see how to
and model the workload scalability profile. You will see how to measure latency, CPU instruction and cycles (
The first observation that got me started with the investigations in this post is that reading
Parquet files with Spark is often a CPU-intensive operation. A simple test to realize this is by reading a test table using a Spark job running with just one task/core and measure the workload using Spark. This is the subject of the first experiment:
Lab 1: Experiment with reading a table from Parquet and measure the workload
The idea for this experiment is to run a Spark job to read a test table stored in Parquet format (see lab setup details above). The job just scans through the table partitions with a filter condition that is written in such a way that it is never true for the given test data, this has the effect of generating I/O to read the entire table, producing a minimal amount of overhead for processing and returning the result set (which will be empty). From more details of how this "trick" works, see the post "
Diving into Spark and Parquet Workloads, by Example".
One more prerequisite, before starting the test, is to clean the file system cache, this ensure reproducibility of the results if you want to run it the test multiple times:
# drop the filesystem cache before testing
# echo 3 > /proc/sys/vm/drop_caches
# startup Spark shell with additional instrumentation using spark-measure
$ bin/spark-shell --master local[1] --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11 --driver-memory 16g
// Test workload
// This forces reading the entire table
// Disable filter pushdown so the filter is applied to all the rows
spark.conf.set("spark.sql.parquet.filterPushdown","false")
val df = spark.read.parquet("/data/tpcds_1500/web_sales")
val stageMetrics = ch.cern.sparkmeasure.StageMetrics(spark)
stageMetrics.runAndMeasure(df.filter("ws_sales_price=-1").collect())
The output of the Spark instrumentation is a series of metrics for the job execution. The metrics are collected by Spark executors and handled via Spark listeners (see additional details on
sparkMeasure, at this link). The measured metrics for the test workload on Lab 1 are:
What you can learn from this test and the collected metrics values:
- The workload consists in reading one partitioned table, the web_sales table part of the TPCDS benchmark. The table size is ~68 GB (it has ~1 billion rows), generated as described above in "Lab setup".
- From the metrics you can see that the query ran in about 8 minutes, with only one active task at a time. Note also that "executor time" = "elapsed time" in this example.
- Most of the execution time was spent on CPU. Other metrics about time measures (serialization/deserialization, garbage collection, shuffle), although of importance in general for Spark workloads, can be ignored in this example as their values are very close to zero.
- The difference between between the elapsed time and the CPU time can be interpreted as the I/O read time (more on this later in this post). The estimated value of the time spent on I/O amounts to ~ 30% of the total execution time. Further in this post you can see how to directly measure I/O time and confirm this finding.
- We conclude that the workload is mostly CPU-bound
Lab 2: focus on the CPU time of the workload
This experiment runs the same query as experiment 1, with one important change: data is read entirely from
file system cache in this second experiment. This happens naturally in a test system with enough memory (assuming that no other workload of importance runs there). Reading data from filesystem cache brings to zero the time spend waiting for the slow response time of the HDD and provides an important boost to I/O performance: this is as if the system was attached to
fast storage. The test machine used did not have fast I/O, however in a real-world data system we may expect to have a fast storage subsystem, as a SSD or NVMe or a network-based filesystem over 10 GigE. This is probably a more realistic scenarios than reading from a local disk and further motivates the tests proposed here, where I/O is served from filesystem cache to decouple the measurements from HDD response time. The results for the key metrics in the case of reading the test Parquet table from the filesystem cache (using the same SQL as in Lab 1) are:
...
elapsedTime => 316575 (5.3 min)
sum(stageDuration) => 316575 (5.3 min)
sum(executorRunTime) => 315270 (5.3 min)
sum(executorCpuTime) => 310535 (5.2 min)
sum(executorDeserializeTime) => 867 (0.9 s)
sum(executorDeserializeCpuTime) => 874 (0.9 s)
sum(resultSerializationTime) => 13 (13 ms)
sum(jvmGCTime) => 4961 (5 s)
...
sum(recordsRead) => 1079971165
sum(bytesRead) => 72942144585 (67.9 GB)
What you can learn from this test:
- The workload response time i Lab 2 isalmost entirely due to time spent on CPU by the executor.
- With some simple calculation you can find that one single Spark task/core on the test machine can process ~220 MB/s of data in Parquet format (this is computed diving the "bytes Read" / "executor Run Time").
Note: Spark task workload metrics still report reading ~68 GB of data in this experiment, as data comes in via the OS read call. Data is actually being served by OS cache, so no physical I/O is happening to serve the read, a fact unknown to Spark executors. You need OS tools to find this, which is the subject on the next lab.
Lab 3: Measure Spark workload with OS tools
This is about using OS tools to measure systems resource utilization for the test workload. By contrast, the Spark workload metrics you have seen so far in the results of experiments 1 and 2 are measured by the Spark executor itself. If you are interested in the details, you can see the code of how this is done in
Executor.scala, for example, the CPU time metric is collected using
ThreadMXBean and the method getCurrentThreadCpuTime(), Garbage collection time comes from the
GarbageCollectorMXBean and the method getCollectionTime().
This experiment is about measuring
CPU usage with OS tools and comparing the results with the metrics reported by Spark Measure (as in the tests of Lab 1 and 2). There are multiple tools you can use to measure process CPU usage in Linux, ultimately with instrumentation coming from /proc filesystem. This is an example of using the
Linux comman ps:
# use this to find pid_Spark_JVM
$ jps | grep SparkSubmit
# measure cpu time
$ ps -efo cputime -p <pid_Spark_JVM>
... run test query in the spark-shell as in Lab 2 and run again:
$ ps -efo cputime -p <pid_Spark_JVM>
Just take the difference of the 2 measurements of CPU time. The results for the test system and workload (Spark SQL query reading from Parquet) is:
CPU measured at OS level: 446 seconds
What you can learn from this test:
- By comparing the CPU measurement with OS tools (this Lab) with the result of Lab 2: sum(stageDuration) => 316575 and sum(executorCpuTime) => 310535 you can conclude that the executor consumes in reality more CPU than reported by Spark metrics.
- This is because additional threads are run in the JVM besides the task executor. Note: in these tests only 1 task is executed at a time, this is done on purpose for ease of troubleshooting.
What about
I/O activity ? There are multiple tools for measuring I/O, the following example uses
iotop to measure I/O detailed by OS thread
Results: By running "
iotop -a" on the test machine (the option -a is to collect cumulative metrics) while the workload of Lab 1 runs (after dropping the filesysytem cache) I have confirmed that indeed 68 GB of data were read from disk. In the case of Lab 2, reading a second time the same table, therefore using the filesystem cache, "iotop -a" confirms that the amount of data physically read from the disk device is 0 in this case. Additional measurements to confirm that the I/O goes through the filesystem cache can be done using
tracing tools. As an example I have used
cachestat from perf-tools. Note that RATIO = 100% in the reported measurements means that the tool has measured that I/O was being served by filesystem cache:
# bin/cachestat 5
Counting cache functions... Output every 5 seconds.
HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
281001 0 205 100.0% 215 70648
280151 2 8 100.0% 215 70648
Dynamic tracing: Measuring the latency of I/O calls is a good task for dynamic tracing tools, like
SystemTap,
bcc/BPF,
DTrace. Earlier in this post, I commented that in Lab 1 the query execution spent 70% of its time on CPU and
30% of the time was spent on I/O (reading from Parquet files): the CPU time is a direct measurement reported via Spark metrics, the time spent on I/O is inferred from subtracting the total executor time from CPU time.
It is possible to directly measure the time spent on I/O using a
SystemTap script to measure I/O latency of the "read" calls. An example of the script used for this test is:
# stap read_latencyhistogram_filterPID.stp -x <pid_JVM> 60
Using this I have
confirmed with a direct measurement that I/O time (reading from Parquet files) is indeed responsible for 30% of the workload time as described in Lab 1. In general dynamic tracing are powerful tools for investigating beyond standard OS tools. See also
this link for a list of useful OS tools.
Lab 4: Drilling down with stack profiling and flame graphs
Stack profiling and on-CPU Flame Graph visualization are useful techniques and tools for investigating CPU workloads, see also
Brendan Gregg's page on Flame Graphs.
Stack
profiling helps in understanding and drilling-down on "hot code":
you can find which parts of the code spend considerable amount of
time on CPU and this provides insights for troubleshooting.
Flame graph visualization of the stack profiles brings additional value, besides being an appealing interface, it provides
context about the running code. In particular flame graphs provide information on the
parent functions, this can be used to match the names of the functions consuming CPU resources and their parents with the application architecture/code. There are other methods to represent stack profiles, including reporting a summary or representing it in a tree view.
Nitsan Wakart in "Exploring Java Perf Flamegraphs" explains the advantages of using flame graphs and compares a few of the available tools for collecting stack profiles for the JVM. See also
notes and examples of how to use tools for stack sampling and flame graph visualization for Spark at this link.
What you can learn from the flame graph:
- The flame graph shows the stack traces of the parts of the code that take most of the time. Code paths for execution of Spark data sources and "Vectorized Parquet Reader" are clearly occupying most of the trace samples (i.e. are taking most of the CPU time).
- You can see also that the execution is under "whole stage code generation", another important feature of Spark 2.x (see also the discussion in the blog entry "Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs".
There are many interesting details to explore in the flame graph, for this it is best to use
SVG version with the
zoom feature (click on the graph to zoom) and the search feature (use Control-F).
See also the exercise at the end of Lab 5 and the memory heap profile in Lab 6.
Lab 5: Measuring the benefits of using compression
The Parquet files used in the previous tests are compressed using
snappy compression. This is the default compression algorithm used when writing Parquet files in Spark: you can check this by running spark.conf.get("spark.sql.parquet.compression.codec").
Compression/decompression takes CPU cycles, this exercise is about measuring how much of the workload time is due to decompression of the Parquet files. A simple test is to create a copy of the table without compression and then run the test SQL against it. The table copy can be created with the following code:
val df = spark.table("web_Sales")
df.write
.partitionBy("ws_sold_date_sk")
.option("compression","none")
.parquet("<path>/web_sales_compress")
The next step is running a SQL statement to
read the entire table (similarly to previous Labs, this time, however, using the non-compressed table data). As in the case of Lab 2 above the test is done after caching the table in the file system cache, which happens naturally on a system with enough memory after running the query a couple of times. The metrics collected with sparkMeasure when running the test are:
Scheduling mode = FIFO
Spark Context default degree of parallelism = 1
Aggregated Spark stage metrics:
numStages => 1
sum(numTasks) => 796
elapsedTime => 259021 (4.3 min)
sum(stageDuration) => 259021 (4.3 min)
sum(executorRunTime) => 257667 (4.3 min)
sum(executorCpuTime) => 254627 (4.2 min)
sum(executorDeserializeTime) => 858 (0.9 s)
sum(executorDeserializeCpuTime) => 896 (0.9 s)
sum(resultSerializationTime) => 9 (9 ms)
sum(jvmGCTime) => 3220 (3 s)
sum(shuffleFetchWaitTime) => 0 (0 ms)
sum(shuffleWriteTime) => 0 (0 ms)
max(resultSize) => 1076538 (1051.0 KB)
sum(numUpdatedBlockStatuses) => 0
sum(diskBytesSpilled) => 0 (0 Bytes)
sum(memoryBytesSpilled) => 0 (0 Bytes)
max(peakExecutionMemory) => 0
sum(recordsRead) => 1079971165
sum(bytesRead) => 81634460367 (76.0 GB)
sum(recordsWritten) => 0
sum(bytesWritten) => 0 (0 Bytes)
sum(shuffleTotalBytesRead) => 0 (0 Bytes)
sum(shuffleTotalBlocksFetched) => 0
sum(shuffleLocalBlocksFetched) => 0
sum(shuffleRemoteBlocksFetched) => 0
sum(shuffleBytesWritten) => 0 (0 Bytes)
sum(shuffleRecordsWritten) => 0
Learning points:
- The query execution time is ~ 4.3 minutes and the non-compressed test table size is 76.0 GB (~ 12% larger than the snappy-compressed table).
- The workload is CPU-bound and the execution time reduction compared to Lab 2 is about 20%.
- The query execution time is faster on the non-compressed table than in the case of Lab 2, using the snappy-compressed table. This can be explained as fewer CPU cycles are spent processing the table in this case, as decompression is not needed. The fact that the non-compressed table is larger (of about 12%) does not appear to offset the increase in speed in this case.
- Decompression is an important part of the SQL workload used in this post, but only a fraction of the computing time is spend on decompression, this part of the workload appears not to be responsible for the bulk of the CPU time used.
Comment: this test is consistent with the general finding that snappy is a lightweight algorithm for data compression and suitable for working with Parquet files for data analytics in many cases.
Exercise: the fact that the use of snappy-compresses files is responsible only for a small percentage of the test workload can also be predicted by analyzing the flame graph shown in Lab 4. To do this search (using CONTROL-F) for "decompress" on the SVG version of the flame graph. You will find that a few methods of the flame graph containing the keyword "decompress" are highlighted. You should find that only a fraction of the time is spent in decompression activities, in agreement with the conclusions of this Lab.
Lab 6: Measuring the effect of garbage collection
Heap memory management is an important part of the activity of the JVM. Systems resource utilization for Garbage Collection workload can also be non-negligible and overall show up as considerable overhead to the processing time. The experiments proposed so far have been run with a "generously sized" heap (i.e. --driver-memory 16g) to steer away from such issue. In the next experiment you will see what happens when reading the test table using the default values for spark-shell/spark-submit, that is --driver-memory 1g.
Results of selected metrics when reading the test Parquet table with one executor and --driver-memory 1g:
Spark Context default degree of parallelism = 1
Aggregated Spark stage metrics:
numStages => 1
sum(numTasks) => 787
elapsedTime => 469846 (7.8 min)
sum(stageDuration) => 469846 (7.8 min)
sum(executorRunTime) => 468480 (7.8 min)
sum(executorCpuTime) => 304396 (5.1 min)
sum(executorDeserializeTime) => 833 (0.8 s)
sum(executorDeserializeCpuTime) => 859 (0.9 s)
sum(resultSerializationTime) => 9 (9 ms)
sum(jvmGCTime) => 163641 (2.7 min)
Additional measurements of the CPU time using OS tools (ps -efo cputime -p <pid_of_SparkSubmit>) report CPU time = 2306 seconds.
Lessons learned:
- The execution time of the test SQL statement (reading a Parquet table) increases significantly when the heap memory is decreased to the default value of 1g. Spark metrics report that additional 2.7 minutes are spent on garbage collection time in this case. The garbage collection time is added to the CPU time used for table data processing, with the net effect of increasing the query execution time of ~50%.
- The additional processing for garbage collection also consumes extra CPU cycles in the system. Spark metrics report that the CPU time used by the executor does not increase (it stays at about 300 seconds, as in the case of previous tests), however OS tools show that the JVM process overall takes ~2300 seconds of CPU time, which represents a staggering 7-fold overhead on the amount of CPU used by the executor (300 seconds). Additional investigations show that the extra CPU time is used by multiple threads in the JVM related to the extra work needed by garbage collection.
Heap memory usage can be traced using
async-profiler and displayed as a heap memory flame graph (see also the discussion of on-CPU flame graphs in Lab 4). The resulting heap memory flame graph for the test workload is reported in the figure here below. You can see there that Parquet reader code allocates large amounts of heap memory. Data have been collected using "./profiler.sh -d 315 -m heap -o collapsed -f myheapprofile.txt <pid_Spark_JVM>",
see also this link.
Follow this link for the SVG version of the heap memory flame graph.
Lab 7: Measuring IPC and memory throughput
The experiments discussed so far show that the test workload (reading a Parquet table) is CPU-intensive. In this paragraph you will see how to further drill down on what this means.
Measuring CPU utilization at the OS-level is easy, for example you have seen earlier in this post that Spark metrics report executor CPU time, you can also use OS tools to measure CPU utilization (see Lab 3 and also
this link). What is more complicated, is to
drill down in the CPU workload and understand what the CPU cores do when they are busy.
Brendan Gregg has covered the topic of measuring and understanding CPU workloads in a popular blog post called "
CPU Utilization is Wrong". Other resources with many details are "
A Crash Course in Modern Hardware" by Cliff Click and
Tanel Poders's blog posts on "
RAM is the new disk". Overall the subject appears quite complex, with many details that are CPU-model-dependent. I just want to stress a few key points relevant to the scope of this post.
One of the key points is that it is important to measure and understand the efficiency of the CPU utilization and being able to find answers to question that drill down in CPU workload like: are CPU cores executing
instructions as fast as the CPU cores allow, if not why? How many cycles are being "wasted" stalling and in particular
waiting for cache misses on
memory I/O? Are branch misses important for my workload? etc.
Ideally, we would like to be able to measure the
time the CPU spends in different areas of its activity (instruction execution, stalling etc), such a direct measure is currently not available to my knowledge, however modern CPUs have instrumentation in the form of
hardware counters ("Performance Monitoring Counters",
PMC, that allow to further drill down beyond the CPU utilization numbers you can get from the OS.
Instructions and cycles are two key metrics, often reported as a ratio instructions over cycles,
IPC or the reverse, cycles over instructions CPI, to understand if CPU cores are mostly executing instructions or stalling (for example for cache misses). On Linux, "
perf" is a reference tool to measure PMCs. Perf can also measure many more metrics, including cache misses, which are an important cause of stalled CPU time. Metrics measured with perf for the test workload of reading a Parquet table (as in Lab 2 above) are reported here below (measured using "
perf stat"):
# perf stat -a -e task-clock,cycles,instructions,branches,branch-misses -e stalled-cycles-frontend,stalled-cycles-backend -e cache-references,cache-misses -e LLC-loads,LLC-load-misses,LLC-stores,LLC-store-misses -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores,L1-dcache-store-misses -p <pid_Spark_JVM>
Performance counter stats for process id '12345':
345151.182659 task-clock (msec) # 1.100 CPUs utilized
748,844,357,817 cycles # 2.170 GHz (38.60%)
1,259,538,420,042 instructions # 1.68 insns per cycle (46.28%)
158,154,239,473 branches # 458.217 M/sec (46.31%)
1,628,794,907 branch-misses # 1.03% of all branches (46.33%)
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
28,214,731,947 cache-references # 81.746 M/sec (46.34%)
6,756,246,371 cache-misses # 23.946 % of all cache refs (46.35%)
4,967,291,822 LLC-loads # 14.392 M/sec (30.69%)
1,346,955,145 LLC-load-misses # 27.12% of all LL-cache hits (30.80%)
7,974,695,379 LLC-stores # 23.105 M/sec (15.41%)
1,627,016,422 LLC-store-misses # 4.714 M/sec (15.39%)
360,746,862,614 L1-dcache-loads # 1045.185 M/sec (23.09%)
31,109,549,485 L1-dcache-load-misses # 8.62% of all L1-dcache hits (30.77%)
170,609,291,683 L1-dcache-stores # 494.303 M/sec (30.74%)
<not supported> L1-dcache-store-misses
313.666825089 seconds time elapsed
Comments on IPC measurements with perf stat:
- The metrics collected by perf show that the workload is CPU-bound: there is only one task executing in the system and the equivalent of one CPU core is reported as utilized on average during the job execution. To be more precise, the measurements show that the utilization is about 10% higher than 1 CPU-core equivalent, an overhead that is consistent with the finding discussed earlier on measuring CPU utilization with OS tools.
- Relevant to this discussion are the measurement of cycles and instructions: number of instructions ~ 1.3E12 and number of cycles ~7.5E11. The ratio of the two, instructions per cycle: IPC ratio ~1.7
- Using Brendan Gregg's heuristics, the measured IPC of 1.7 can be interpreted as being generated by an instruction-bound workload. Later in this post you will find additional comments on this in the context of concurrent execution.
- Note: each core of the CPU model used in this test (Intel Xeon CPU E5-2630 v4) can retire up to 4 instructions per cycle. You can expect to see IPC values greater than 1 (up to 4) for compute-intensive workloads, while IPC values are expected to drop to values lower than 1 for memory-bound processes that stall frequently trying to read from memory.
Comments on cache utilization and cache misses:
- In the metrics reported for the perf stat output you can see a large number of load and store operations on CPU caches. The test workload is about data processing (reading and Parquet files and applying a filter condition), so it makes sense that data access is an important part of what the CPUs need to process.
- L1 caches utilization in particular, appears to be quite active in serving a large number of requests: the sum of L1-dcache-stores and L1-dcache-loads mounts to almost 50% of the value of "instructions". Operations that access L1 cache are relatively fast, so you can expect them to cause stalls of short duration (the actual details vary as different CPUs models may have various optimizations in place to reduce the impact of stalls). Note also the value of L1-dcache-load-misses, these are reported to be below 10% of the total loads, however their impact can still be significant.
- In the reported metrics you can also find details on the number of LLC (last level cache) loads, stores and most importantly the number of LLC misses. LLC misses are expensive operations as they require memory access.
Further drill down on CPU-to-DRAM access
The measurements with perf stat show that the test workload is
instruction-intensive, but has also an important component of
CPU-to-memory throughput. You can use additional information coming from hardware counters to further drill down on memory access. A few handy tools are available for this:
see this link for additional information on tools to measure memory throughput in Linux.
In the following I have used
Intel's performance counter monitor (pcm) tool to measure the test workload. This is a snippet of the output of pcm when measuring the test workload (note the full output is quite verbose and contains more information, see
this link for an example):
# ./pcm.x <measurement_duration_in_seconds>
...
Intel(r) QPI traffic estimation in bytes (data and non-data traffic outgoing from CPU/socket through QPI links):
QPI0 QPI1 | QPI0 QPI1
--------------------------------------------------------------------
SKT 0 191 G 191 G | 3% 3%
SKT 1 169 G 169 G | 3% 3%
--------------------------------------------------------------------
Total QPI outgoing data and non-data traffic: 721 G
MEM (GB)->| READ | WRITE | CPU energy | DIMM energy
-------------------------------------------------------------------
SKT 0 333.67 469.09 6516.63 2697.37
SKT 1 279.68 269.33 10062.19 4048.73
------------------------------------------------------------------- * 613.36 738.42 16578.81 6746.10
Key points and comments on CPU-to-memory throughput measurements:
- The measured data transfer to and from main memory is 613.36 GB (read) + 738.42 GB (write) = ~1350 GB of total "CPUs-memory traffic".
- The execution time of the tests is ~310 seconds (not reported in the data of this Lab, see Lab 2 metrics).
- The measured average throughput between CPU and memory for the job is ~ 4.3 GB/s
- For comparison the CPU specs at ark.intel.com list 68.3 GB/s as the maximum memory bandwidth for the CPU model used in this test.
- The CPUs used for these tests use the Intel Quick Path Interconnect QPI to access memory. There are 4 links in total in the system (2 links per socket). The measured QPI utilization is ~3% in this test.
- "Low memory throughput": For the current CPU model it appears that the measured throughput of 4 GB/s and QPI utilization of 3% can be considered as low utilization of the CPU-to-memory channel. I have reached this tentative conclusion by comparing with a memory-intensive workload on the same system generated with the Stream memory test by John D. McCalpin (see also more info at this link). In the case of "Stream memory test" run using only one thread, I could measure QPI utilization of ~12% and and measure CPU-to-memory throughput of about 14 GB/s. This is about 3-4 time more than with the test workload of the Labs in this post and therefore appears to further justify the statement that memory throughput is low for the test workload (reading a Parquet table).
- "Front-end and back-end workload": It is interesting to compare the figures of DRAM throughput with the measured data processing throughput as seen from the users and similarly, how much of the original table data in Parquet is processed vs the amount of memory moved between DRAM and CPU. There is a factor 20 in volume between the original table size and the amount of memory processed: The measured throughput between CPU and memory is ~4.3 GB/s, the measured throughput of Parquet data processing is 220 MB/s. The size of the test table in Parquet is 68 GB, while roughly 1.3 TB of data have been transferred between memory and CPU processed during the workload (read + write activity).
Conclusions
- From measurements of the CPU hardware counters it appears that the test workload is CPU-bound and instruction-intensive, however it also has an important component of data transfer between CPU and main memory. More on this topic will be covered later in this post in the analysis of the workload at scale.
- The efficiency of the code used to process Parquet data appears to have room for optimizations, in particular the amount of data processed in memory is measured to be more than 1 order of magnitude larger than the size of the Parquet table being processed.
Recap of lessons learned in Part 1 of this post
- Reading from Parquet is a CPU-intensive activity.
- You need to allocate enough heap memory for your executors to avoid large overheads with the JVM garbage collector.
- The test system can process ~ 200 MB per second of Parquet data on a single core for the given test workload. The CPU workload is mostly instruction-bound, the utilization of the channel CPU-memory is low.
- There are many tools you can use to measure Spark workloads: Spark task metrics and OS tools to measure CPU, I/O, network, memory, stack profiling with flame graph visualization and dynamic tracing tools.
Part 2: Scaling up the workload
TLDR;
- The test workload, reading from a Parquet partitioned table, scales up on a 20-core server.
- The workload is instruction-bound up to 10 concurrent tasks, at higher load it is limited by CPU-to-memory bandwidth.
- CPU utilization metrics can be misleading, drill down by measuring instruction per cycle (IPC) and memory throughput. Beware of hyper-threading.
Lab 8: Measuring elapsed time at scale
In the experiments described so far you have seen how the test workload (reading from a Parquet partitioned table) runs on Spark using a single task and how to measure it in some simple and controlled cases. Distributed data processing and Spark are all about
running tasks concurrently, this is the subject of the the rest of this post.
The test machine I used has 20 cores (2 sockets, with 10 cores each, see also Lab setup earlier in this post). The results of running the workload with increasing number of concurrent tasks is summarized in the following table:
| Concurrent Tasks (N#) |
Elapsed time (millisec) |
| 1 |
315816 |
| 2 |
151787 |
| 3 |
102726 |
| 4 |
76959 |
| ... | ... |
| 19 |
20638 |
| 20 |
19917 |
Key takeaway point from the table:
- As the number of concurrent tasks deployed increases, the job duration decreases, as expected.
- The measurements show that elapsed time drops from about 5 minutes, in the case of no parallelism, down to 20 seconds, when 20 CPU cores are fully utilized.
- The next question is to quantify how well the workload scales on multiple CPU cores, which is the subject of the next Lab.
Note on the measurement method: measurements in the top scale of the number of concurrent tasks shows an important amount of time spent on garbage collection (jvmGCTime) in their first execution. In subsequent executions the garbage collection time is gradually reduced to just a few seconds. The measurement reported here are collected after a few "warm up runs" of the query (typically around 3 "warm up" runs before measuring). For similar reason the parameter --driver-memory is "oversize" to a high value (typically 32g * num_executors).
Lab 9: How well does the workload scale?
A useful parameter to study scalability is the "
Speedup": if you execute your job with "p" (as in parallel) concurrent processes, Speedup(p) is defined as the response time of the job at concurrency p divided the response time of the job run with p=1. If you prefer a formula: Speedup(p) = R(1)/R(p).
The expected behavior for the speedup of a
perfectly scalable job will show as a straight line in a graph of speedup vs. number of concurrent tasks: the amount of work is directly proportional to the number of workers in this case. Any bottleneck and/or
serialization effect will cause the graph of the speedup to eventually "bend down" and lay
below the "ideal case" of linear scalability. See also how the speedup can be modeled using
Amdahl's law.
The following table and graph show the measurements of Lab 8 (query execution time for reading the test table of 68 GB) transformed into speedup values vs. N# of executors:
p=N#
executors
|
Elapsed time (s)
|
Speedup(p)
|
| 1 |
311302 |
1.00 |
| 2 |
149673 |
2.08 |
| 3 |
100194 |
3.11 |
| 4 |
75547 |
4.12 |
| 5 |
60931 |
5.11 |
| 6 |
51342 |
6.06 |
| 7 |
44165 |
7.05 |
| 8 |
39613 |
7.86 |
| 9 |
35450 |
8.78 |
| 10 |
32061 |
9.71 |
| 11 |
29436 |
10.58 |
| 12 |
27735 |
11.22 |
| 13 |
25764 |
12.08 |
| 14 |
24021 |
12.96 |
| 15 |
23217 |
13.41 |
| 16 |
22092 |
14.09 |
| 17 |
21016 |
14.81 |
| 18 |
20647 |
15.08 |
| 19 |
19999 |
15.57 |
| 20 |
19989 |
15.57 |
Lessons learned:
- The speedup grows almost linearly, at least up to about 10 concurrent tasks.
- This can be interpreted as a sign that the workload scales and does not encounter bottlenecks at least up to the measured scale.
- At higher load you can see that the speedup reaches a saturation zone. Drilling down on this is the subject of the next Lab.
Lab 10: CPU utilization, instructions, cycles and memory at scale
CPU utilization is a metric that does not reveal many insights about the nature of the workload. Measuring CPU
instructions and
cycles helps in
understanding if the workload is instruction-bound or memory-bound. Also measuring the
throughput between CPU and
memory is important for data-intensive workloads as the one tested here.
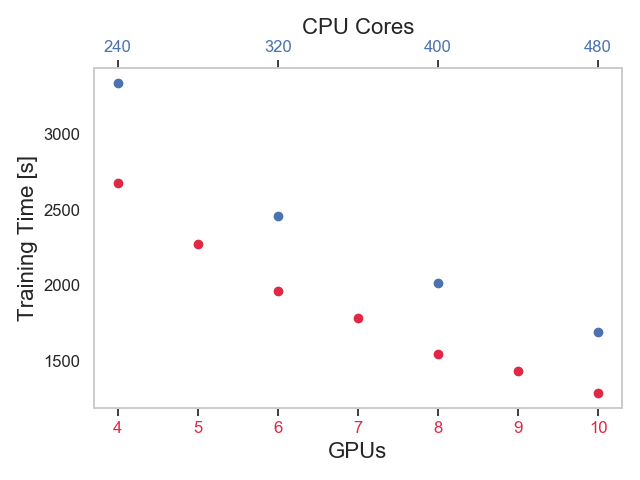
The following graph reports the measurement of the CPU-to-memory throughput for the test workloads measured using
Intel's pcm (see also this link for more info).
CPU-to-memory traffic measurement at high load - Here below some key metrics measured in the test with 20 concurrent tasks executing the test workload:
- The measured throughput of data transfer between CPU and memory is about 84 GB/s (55% of which is writes and 45% reads).
- Another important metric is the utilization of the QPI links, there are 4 links in total in the system (2 links per socket). The measured QPI utilization is ~65% for the test with 20 concurrent processes.
Comparing with benchmarks - The question I would like to answer is: I have measured 84 GB/s of CPU-to-memory throughput, is that a high value for my test system? To approach the problem I have used a couple of benchmark tools to generate high load on the system: John D. McCalpin's stream memory test and Intel memory latency latency checker,
see further details on those tools at this link. The test system during the stress tests has reached up to 100 GB/s of CPU-to-memory throughput with the benchmark tools. By comparing the benchmark values with the measured throughput of 84 GB/s I am tempted to conclude that the
test workload (reading a Parquet table)
stresses the system towards
saturation levels of the CPU-to-
memory channel at high load (with 20 cores busy executing tasks).
IPC measurement under load - Another measure hinting that the CPUs are spending an increasing amount of time in stalled cycles at high load, comes from the measurement of instruction per cycle (IPC). The number of instructions for the test workload (reading 68 GB of a test Parquet table) stays constant at about 1.3E12 instructions at various load levels (this number can be measured with perf for example). However, the number of cycles needed to process the workload increases with load. Measurements on a the test system are reported in the following figure:

Comments on IPC measurements - By comparing the graph of job speedup and the graph of IPC, you can see that the drop in IPC corresponds to the inflection point in the scalability graph, around a number of concurrent tasks ~10. This is a good hint that serialization mechanism are in place to limit the scalability when the load is higher than 10 concurrent tasks (for the test system used).
Additional notes on the measurements of IPC at scale:
- The measurements reported are an average of the IPC values measured over the duration of the job, there is more structure to it when looking at a finer time scale, which is not reported here.
- The measured amount of data transferred between CPU and memory shows a slow linear increase with number of concurrent tasks (from ~1300 GB at N# tasks=1 to 1.6 TB at N# tasks=20).
Lessons learned:
- The test workload in this post (reading a partitioned Parquet table) when run with concurrently executing tasks, scales up linearly to about 10 concurrent tasks, then the scalability appears affected by the higher utilization of the CPU-memory channels.
- The highest throughput of the test with Spark SQL measured with 20 concurrent tasks is ~3.4 GB/s of Parquet data processed and this correspond to ~84 GB/s throughput between CPUs and memory.
- As noted in Lab 7, to process 68 GB of parquet data in the test workload used in this post, the system has accessed more than 1 TB of memory. Similarly, at high load the throughput observed at the user-end is of about 3.4 GB/s RAM while the system throughput at systems level at 84 GB/s. The high ratio of useful work done compared to the system load hints to possible optimizations in the Parquet reader.
Lab 11: Understanding CPU metrics with hyper-threading and pitfalls when measuring CPU workloads on multi-tenant systems
In this section I want to drill down on a few
pitfalls when measuring CPU utilization. The first one is about
CPU Hyper-Threading.
The server used for the tests reported here has hyper-threading activated. In practice this means that the OS sees "40 CPU" (see for example /proc/cpuinfo), while the actual number of cores in the system is 20. In the previous Labs you have seen how the test workload scales up to 20 concurrent tasks, the number 20 being the number of cores in the system. In that "load regime" the OS appeared to be able to schedule the tasks and utilize the available CPU cores to scale up the workload (the test system was dedicated to the tests and did not have any other relevant load). The following test is about scaling up to 40 concurrent tasks and comparing with the case of 20 concurrent tasks.
| Metric |
20 concurrent tasks |
40 concurrent tasks |
| Elapsed
time |
20 s |
23 s |
| Executor run time |
392 s |
892 s |
| Executor
CPU Time |
376 s |
849 s |
| CPU-memory data volume |
1.6 TB |
2.2 TB |
| CPU-memory
throughput |
85 GB/s |
90 GB/s |
| IPC |
1.42 |
0.66 |
| QPI
utilization |
65% |
80% |
Lessons learned:
- The response time of the test workload does not improve when going from 20 concurrent tasks up to 40 concurrent tasks.
- The measured SQL elapsed time stays basically constant, actually it increases slightly for the chosen workload. The increase in elapsed time (i.e. a reduction of throughput) can be correlated with the extra work in CPU-to-memory data transfer, that grows with the number of threads utilized by the load (this is also reported in the measurements table).
- The OS scheduler runs 40 concurrent processes/tasks, corresponding to the number of threads in the CPUs, however this does not improve the performance compared to the case of 20 concurrent processes/tasks.
- When CPU utilization goes above 20 concurrent processes, some of the processes are scheduled to run on threads that have to share the same physical cores (up to 2 threads per core in the CPU used in the test system). The end result is that the system behaves as if it was running on slower CPUs (roughly twice slower moving from load= 20 concurrent tasks to load=40 concurrent tasks).
- Gotcha: process utilization and measured CPU time are difficult metrics to interpret and even more so when using hyper-threading, this can be an important point to keep in mind when troubleshooting workloads at high load and/or on multi-tenant systems utilizing shared resources where the additional load can come from other "noisy neighbors".
In the previous paragraphs you have seen that when the number of concurrent tasks goes above the number of available CPU cores in the system, the throughput of the test workload does not increase, even though the OS reports an increasing utilization of the CPU threads.
What happens when the number of concurrent tasks keeps
increasing and goes above the number of available CPU
threads in the system?
This is another case of running on a system with high load and it is a valid case, possibly because you are running on a system shared with other users creating additional load. Here is an example, when running the workload with 60 concurrent tasks (the test system has 40 CPU threads):
| Metric |
20 concurrent tasks |
40 concurrent tasks |
60 concurrent tasks |
| Elapsed
time |
20 s |
23 s |
23 s |
| Executor run time |
392 s |
892 s |
1354 s |
| Executor
CPU Time |
376 s |
849 s |
872 s |
| CPU-memory data volume |
1.6 TB |
2.2 TB |
2.2 TB |
| CPU-memory
throughput |
85 GB/s |
90 GB/s |
90 GB/s |
| IPC |
1.42 |
0.66 |
0.63 |
| QPI
utilization |
65% |
80% |
80% |
Key points:
- At high load the job latency stays constant with increasing load, roughly to the value reached when running with 20 concurrent tasks (that is about 20 seconds, 20 concurrent tasks corresponds to one task per core in the test system).
- The amount of utilized CPU seconds does not increase above the value measured at 40 concurrent tasks. This is explained as the OS can schedule work on 40 "logical CPUs" corresponding to 40 possible concurrent execution threads in the CPUs using hyper-threading.
- When the number of concurrent tasks is higher than the number of available CPU threads (40) the measured CPU utilization time does not increase, while the sum of the elapsed time on the executor processes keeps increasing. The additional executor time measured accounts for time spent waiting in OS scheduler queues.
- Gotcha: The amount of useful work that the system does when executing the test workload at 20, 40 or 60 concurrent tasks is very similar. In all cases the workload is CPU-bound, with high throughput to memory. The measured metrics values CPU time and executor run time can be misleading at high load for the reasons just explained. It is useful to bear in mind this type of examples when troubleshooting workloads on shared/multi-tenant systems, where additional load on the system can come from sources external to your jobs.
Conclusions
CPU-bound workloads are very important in data processing. In particular modern hardware has typically abundance of cores and memory. Technologies like
Spark, Parquet, Hadoop, make data processing at scale easier and cheaper. Techniques and
tools for measuring and
understanding data processing workloads, including their CPU and memory footprint, are important to get the best
value out of your software and hardware investment.
Reading from Parquet is a CPU-bound workload examined in this post. Some of the lessons learned investigating the test workloads are:
- Spark metrics can be used to understand resource usage and workload behavior, with some limitations.
- Use OS-tools to measure CPU, network, disk. Dynamic tracing can drill down on latency. Stack profiling and flame graphs are useful to drill down on hot parts of the code
- CPU utilization does not always give the full picture: use hardware counters to drill down, including instructions and cycles (IPC) and CPU-to-memory throughput.
- Measure your workload, speedup, IPC, CPU utilization, as function of increasing number of concurrent tasks to understand its scalability profile and bottlenecks.
- Watch out for common pitfalls when measuring CPU metrics on multi-tenant systems, in particular be aware if Hyper-threading is used.
Relevant articles and presentations:
- Brendan Gregg's blog post
CPU Utilization is Wrong
- The presentation:
A Crash Course in Modern Hardware by Cliff Click
-
Brendan Gregg's page on Flame Graphs
-
Nitsan Wakart:
Using FlameGraphs To Illuminate The JVM by ,
Exploring Java Perf Flamegraphs
- For related topics in the Oracle context, see
Tanel Poders's blog post
"RAM is the new disk"
-
Intel 64 and IA-32 Architectures, Optimization Reference Manual
-
Intel Tuning Guides and Performance Analysis Papers
Acknowledgements
This work has been done in the context of CERN Hadoop and Spark service and has profited from the collaboration of several of my colleagues at CERN.

 Watch sparkMeasure's getting started demo and tutorial
Watch sparkMeasure's getting started demo and tutorial








{kind=link}
{kind=link}