Are you looking at some resources to get you up to speed with popular Deep Learning and Data processing frameworks? This blog entry provides a curated collection of notebooks that will help you kickstart your journey.
You can find the notebooks at this link. See also the SWAN gallery.
CERN users can run the notebooks on the SWAN platform, using GPU resources.

Other options for running the notebooks in the cloud with a GPU include Google's Colab.
Getting started with Deep Learning
These notebook showcase a digit recognition classifier using the MNIST dataset, which serves as a "Hello World!" for Deep Learning. Choose from the following options to get started:
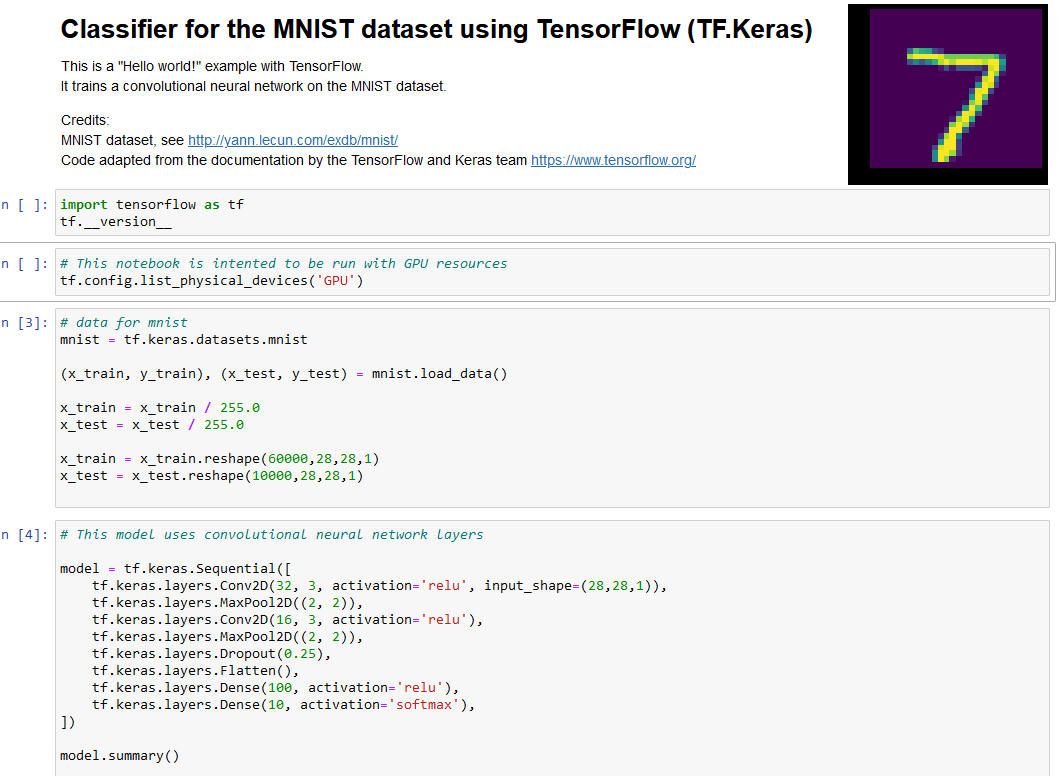
Deep Learning and basic Data pipelines
Learn how to integrate Deep Learning frameworks with basic data pipelines using Pandas to feed data into the DL training step. These notebooks implement a Particle classifier using various DL frameworks. The data is stored in Parquet format, offering efficient data reading.
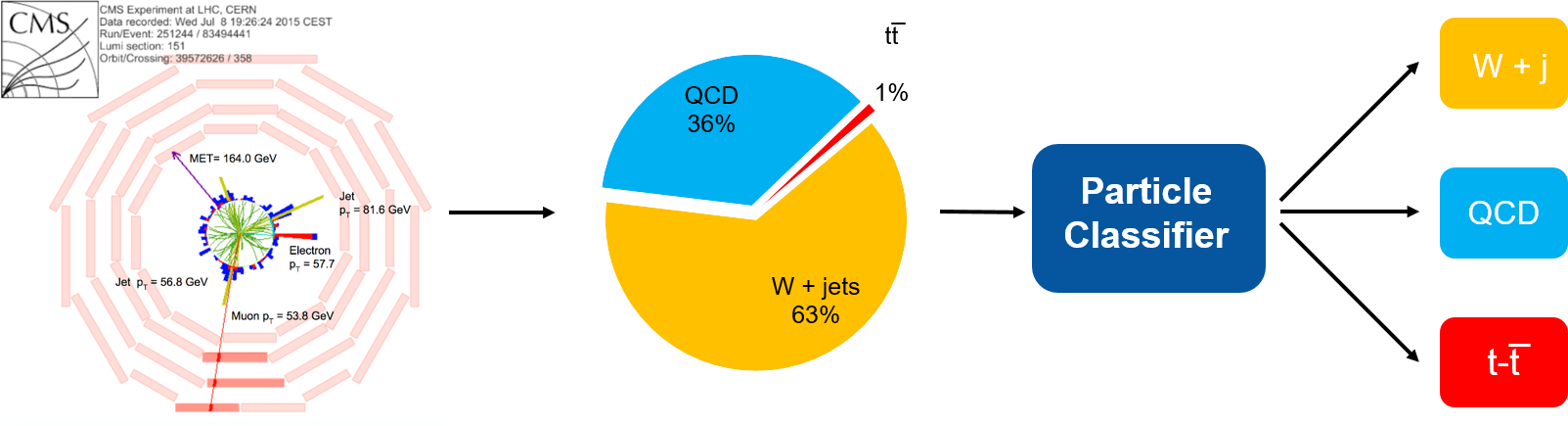
- TensorFlow classifier with data from Pandas
- Pytorch classifier with data from Pandas
- Pytorch Lightning classifier with data from Pandas
- XGBoost classifier with data from Pandas
More advanced Data pipelines
Take your data processing skills to the next level with these notebooks, which demonstrate advanced data pipelines suitable for large datasets. Discover how to leverage the Petastorm library to read data from Parquet files with TensorFlow and PyTorch, as well as utilizing the TFRecord format with TensorFlow.
Additional complexity with models and data
Building upon the previous examples, these notebooks introduce more complex models and larger datasets for the Particle classifier. Explore the capabilities of TensorFlow, GRU, Transformer, and TFRecord with:
- TensorFlow for the Inclusive Classifier, with GRU and TFRecord
- Description: This notebook focuses on training with data stored in TFRecord format.
- TensorFlow is configured to run on a GPU, and an LSTM-based model architecture is employed.
- TensorFlow for the Inclusive Classifier, with Transformer and TFRecord
- Description: This notebook focuses on training with data stored in TFRecord format.
- TensorFlow is configured to run on a GPU, and a Transformer-based model architecture is employed.

AI Tools Examples
Transformers library
Explore the powerful Transformers library from Hugging Face, widely used for LLM, Natural Language Processing (NLP), image, and speech tasks.
- Transformers for text classification
- Transformers for image classifier
- Stable diffusion with transformers
- Transformers for speech recognition
Large language models
These notebooks provide examples of how to use LLMs in notebook environments for tests and prototyping
Semantic search with Vector Databases and LLM
Semantic search allows to query a set of documents. This examples shows how to create vector embeddings, store them in a vector database, and perform semantic queries enhanced with LLM.
Data Tools Examples
This section offers example notebooks featuring popular frameworks and libraries for handling data. Please note that it does not cover scale-out data solutions such as Spark and Dask.
For Apache Spark see SparkTraining
If you require access to relational databases for testing, CERN users can reach out to Oracle and DBOD services. You can also set up test databases using container technology. Here's how:
Running a test Oracle instance on a container:
- Run Oracle Free on a container from gvenzl dockerhub repo https://github.com/gvenzl/oci-oracle-free
- see also https://github.com/gvenzl/oci-oracle-free
docker run -d --name mydb1 -e ORACLE_PASSWORD=oracle -p 1521:1521 gvenzl/oracle-free:latest- Wait until the DB is started (this may take a few minutes). Check progress with:
docker logs -f mydb1 - install the Python library for connecting to Oracle:
pip install oracledb
Setting up a PostgreSQL instance for testing using a Docker image:
docker run --name some-postgres -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgres- wait till the DB is started, check logs at:
docker logs -f some-postgres - install the Python library for connecting to PostgreSQL:
pip install psycopg2-binary
Pandas and numpy examples
Conclusions and acknowledgments
This blog entry provides a valuable collection of exploratory notebooks for individuals who are new to deep learning and data processing. With a focus on popular frameworks and libraries, these notebooks cover a range of topics including digit recognition, transformers for various tasks, integrating deep learning with data pipelines, advanced data processing techniques, and examples of data tools. Whether you are a CERN user or prefer cloud-based platforms like Google's Colab, these notebooks will help you quickly grasp the fundamentals and get started on your deep learning and data processing journey.
I would like to express my sincere gratitude to my colleagues at CERN for their invaluable assistance and insightful suggestions, in particular I'd like to acknowledge the CERN data analytics and web notebook services and ATLAS database and data engineering teams. Their expertise and support have played a crucial role in making this collection of notebooks possible. Thank you for your contributions and dedication.
No comments:
Post a Comment