This blog post is about building a getting-started example for semantic search using vector databases and large language models (LLMs), an example of retrieval augmented generation (RAG) architecture. You can find the accompanying notebook at this link. See also the SWAN gallery.
CERN users can run the notebooks using the SWAN platform and GPU resources.

Other options for running the notebooks in the cloud with a GPU include Google's Colab.
![]()
Goals and Scope
Our primary goal is to demonstrate the implementation of a search engine that focuses on understanding the meaning of documents rather than relying solely on keywords.
The proposed implementation uses resources currently available to CERN users: Jupyter notebooks with GPUs, Python packages from the open source ecosystem, a vector database.
Limitations:it's important to note that this example does not cover building a fully-fledged search service or chat engine. We leave those topics for future work, here were limit the discussion to a getting-started example and a technology demonstrator.
Understanding Key Concepts
Semantic search: Semantic search involves searching for meaning rather than just literal matches of query words. By understanding the context and intent behind the query, semantic search engines can provide more accurate and relevant results.
Vector Database: A vector database is a specialized type of database designed to handle vector embeddings. These embeddings represent data in a way that captures essential semantic information. They are widely used in applications such as large language models, generative AI, and semantic search.
Large Language Models (LLMs): LLMs are powerful language models built using artificial neural networks with a vast number of parameters (ranging from tens of millions to billions). These models are trained on extensive amounts of unlabeled text data using self-supervised or semi-supervised learning techniques.
Implementation details
Building a semantic search prototype has become more accessible due to recent advancements in natural language processing and applied ML/AI. Using off-the-shelf components and integrating them effectively can accelerate the development process. Here are some notable key ingredients that facilitate this implementation:
- Large Language Models (LLMs) and embedding Libraries:
- The availability of powerful LLMs such as OpenAI GPT-3.5 and GPT-4, Google's Palm 2, and of embedding libraries, significantly simplifies the implementation of semantic search and natural language processing in general. These models provide comprehensive language understanding and generation capabilities, enabling us to extract meaning from text inputs.
- Platforms:
- Platforms and cloud services such as Hugging Face offer valuable resources for operating with ML models as these libraries provide pre-trained models, tokenization utilities, and interfaces to interact with LLMs, reducing the implementation complexity.
- Open Source Libraries like LangChain:
- Open source libraries like LangChain provide a convenient way to integrate and orchestrate the different components required for building applications in the semantic search domain. These libraries often offer pre-defined pipelines, data processing tools, and easy-to-use APIs, allowing developers to focus on the core logic of their applications.
- Vector Databases and Vector Libraries:
- Vector libraries play a crucial role in working with semantic embeddings. They provide functionalities for vector manipulation, similarity calculations, and operations necessary for processing and analyzing embedding data. Additionally, vector databases are recommended for advanced deployments, as they offer storage and querying capabilities for embeddings, along with metadata storage options. Several solutions are available in this area, ranging from mature products offered as cloud services to open source alternatives.
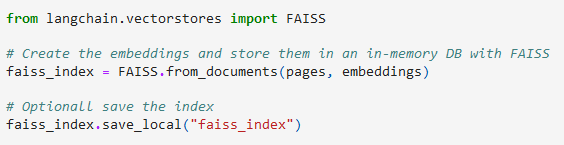
Back-end: prepare the embeddings and indexes in a vector database


Semantic querying using similarity search and vector DB indexes


Grand Finale: a Large Language Model for natural language query capabilities

Conclusions
In this blog post, we have demonstrated how to build a beginner's semantic search system using vector databases and large language models (LLMs). Our example has utilized Jupyter notebooks with GPUs, Python packages, and a vector database, proving that a semantic search engine that queries documents for meaning, instead of just keywords, can be feasibly built using existing resources.
In our implementation, we demonstrated how embeddings and indexing can be performed using FAISS as the vector library, or in alternative with OpenSearch as the vector database. We then moved onto the semantic query process using similarity search and vector DB indexes. To finalize the results, we utilized an LLM to convert the relevant document snippets into a coherent text answer.
Though the example provided is not intended to function as a fully-developed search service, it serves as an excellent starting point and technological demonstrator for those interested in semantic search engines. Additionally, we acknowledge the potential of these methods to handle private documents and produce factually accurate results with original document references.
We believe the combination of semantic search, vector databases, and large language models holds large potential for transforming how we approach information retrieval and natural language processing tasks.
The accompanying notebook, providing step-by-step code and more insights, is accessible on GitHub and via the CERN SWAN Gallery. For researchers and developers interested in delving into this exciting area of applied ML/AI, it offers a working example that can be run using CERN resources on SWAN, and also can run on Colab.
No comments:
Post a Comment