Summary: This post details a solution for distributed deep learning training for a High Energy Physics use case, deployed using cloud resources and Kubernetes. You will find the results for training using CPU and GPU nodes. This post also describes an experimental tool that we developed,
TF-Spawner, and how we used it to run distributed TensorFlow on a Kubernetes cluster.
Authors: Riccardo.Castellotti@cern.ch and Luca.Canali@cern.ch
A Particle Classifier
This work was developed as part of the pipeline described in
Machine Learning Pipelines with Modern Big DataTools for High Energy Physics. The main goal is to build a particle classifier to improve the quality of data filtering for online systems at the LHC experiments. The classifier is implemented using a neural network model described in
this research article.
The datasets used for test and training are stored in
TFRecord format, with a cumulative size of about 250 GB, with 34 million events in the training dataset. A key part of the neural network (see Figure 1) is a
GRU layer that is trained using lists of 801 particles with 19 low-level features each, which account for most of the training dataset. The datasets used for this work have been produced using Apache Spark, see
details and code. The original pipeline produces files in Apache Parquet format; we have used Spark and the
spark-tensorflow-connector to convert the datasets into TFRecord format,
see also the code.
Data: download the datasets used for this work at this link
Code: see the code used for the tests reported in this post at this link
Figure 1: (left) Diagram of the neural network for the Inclusive Classifier model, from
T. Nguyen et. al. (right) TF.Keras implementation used in this work.
Distributed Training on Cloud Resources
Cloud resources provide a suitable environment for scaling distributed training of neural networks. One of the key advantages of using cloud resources is the elasticity of the platform that allows allocating resources when needed. Moreover, container orchestration systems, in particular Kubernetes, provide a powerful and flexible API for deploying many types of workloads on cloud resources, including machine learning and data processing pipelines. CERN physicists, and data scientists in general, can access cloud resources and Kubernetes clusters via the CERN OpenStack private cloud. The use of public clouds is also being actively tested for High Energy Physics (HEP) workloads. The tests reported here have been run using resources from
Oracle's OCI.
For this work, we have developed a custom launcher script,
TF-Spawner (see also the paragraph on TF-Spawner for more details) for running distributed TensorFlow training code on Kubernetes clusters.
Training and test datasets have been copied to the cloud object storage prior to running the tests, OCI object storage in this case, while for tests run at CERN we used an S3 installation based on Ceph. Our model training job with TensorFlow used training and test data in TFRecord format, produced at the end of the data preparation part of the pipeline, as discussed in the previous paragraph. TensorFlow reads natively TFRecord format and has tunable parameters and optimizations when ingesting this type of data using the modules tf.data and tf.io. We found that reading from OCI object storage can become a bottleneck for distributed training, as it requires reading data over the network which can suffer from bandwidth saturation, latency spikes and/or multi-tenancy noise. We followed
TensorFlow's documentation recommendations for improving the data pipeline performance, by using prefetching,
parallel data extraction, sequential interleaving, caching, and by using a
large read buffer. Notably, caching has proven to be very useful for distributed training with GPUs and for some of the largest tests on CPU, where we observed that the first training epoch, which has to read the data into the cache, was much slower than subsequent epoch which would find data already cached.
Tests were run using TensorFlow version 2.0.1, using tf.distribute strategy "multi worker mirror strategy''. Additional care was taken to make sure that the different tests would also yield the same good results in terms of accuracy on the test dataset as what was found with
training methods tested in previous work. To achieve this we have found that additional tuning was needed on the settings of the learning rate for the optimizer (we use the
Adam optimizer for all the tests discussed in this article). We scaled the learning rate with the number of workers, to match the increase in effective batch size (we used 128 for each worker). In addition, we found that slowly reducing the learning rate as the number of epochs progressed, was beneficial to the convergence of the network. This additional step is an ad hoc tuning that we developed by trial and error and that we validated by monitoring the accuracy and loss on the test dataset at the end of each training.
To gather performance data, we ran the training for 6 epochs, which provided accuracy and loss very close to the best results that we would obtain by training the network up to 12 epochs. We have also tested adding shuffling between each epoch, using the shuffle method of the tf.data API, however it has not shown measurable improvements so this technique has not been further used in the tests reported here.
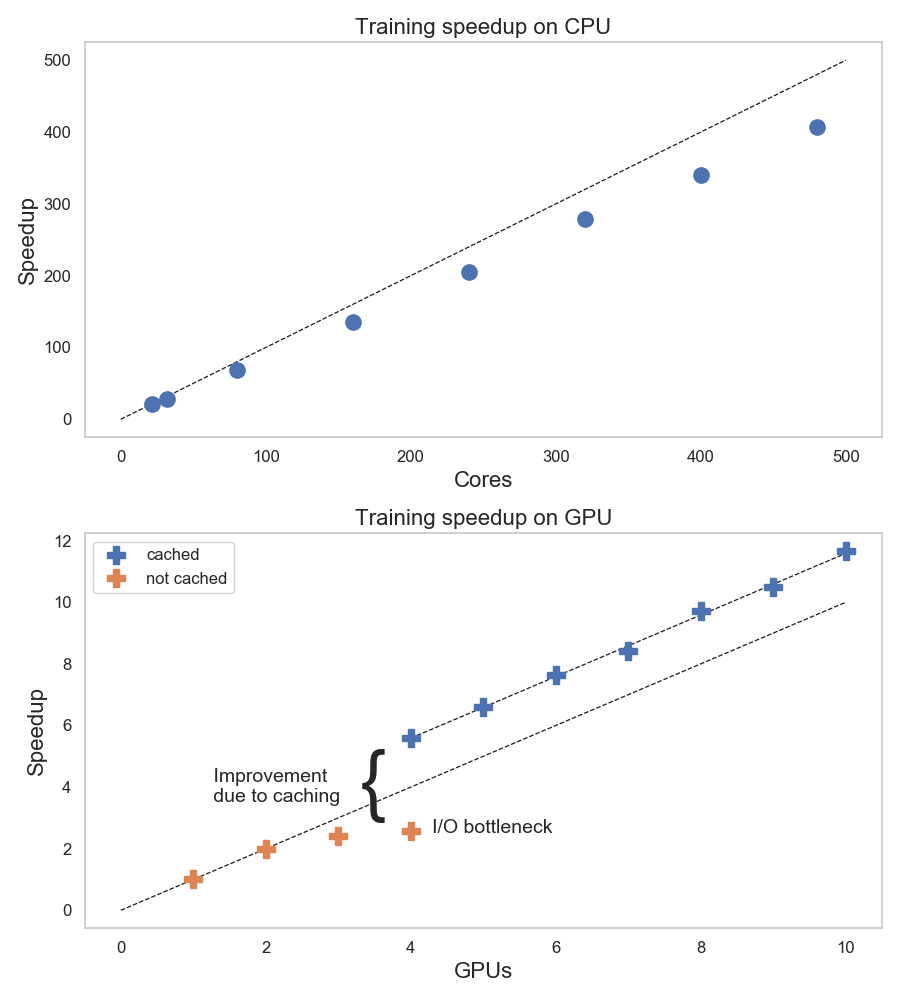
Figure 2: Measured speedup for the distributed training of the Inclusive Classifier model using TensorFlow and tf.distribute with “multi worker mirror strategy”, running on cloud resources with CPU and GPU nodes (Nvidia P100), training for 6 epochs. The speedup values indicate how well the distributed training scales as the number of worker nodes, with CPU and GPU resources, increases.
Results and Performance Measurements, CPU and GPU Tests
We deployed our tests using Oracle's OCI. Cloud resources were used to build Kubernetes clusters using virtual machines (VMs). We used a set of Terraform script to automate the configuration process. The cluster for CPU tests used VMs of the flavor "VM.Standard2.16'', based on 2.0 GHz Intel Xeon Platinum 8167M, each providing 16 physical cores (Oracle cloud refers to this as OCPUs) and 240 GB of RAM. Tests in our configuration deployed 3 pods for each VM (Kubernetes node), each pod running one TensorFlow worker. Additional OS-based measurements on the VMs confirmed that this was a suitable configuration, as we could measure that the CPU utilization on each VM matched the number of available physical cores (OCPUs), therefore providing good utilization without saturation. The available RAM in the worker nodes was used to cache the training dataset using the tf.data API (data populates the cache during the first epoch).
Figure 2 shows the results of the Inclusive Classifier model training speedup for a variable number of nodes and CPU cores. Tests have been run using
TF-Spawner. Measurements show that the training time decreases as the number of allocated cores increases. The
speedup grows close to linearly in the range tested: from 32 cores to 480 cores. The largest distributed training test that we ran using CPU, used 480 physical cores (OCPU), distributed over 30 VM, each running 3 workers each (each worker running in a separate container in a pod), for a total of 90 workers.
Similarly, we have performed tests using GPU resources on OCI and running the workload with
TF-Spawner. For the GPU tests we have used the VM flavor "GPU 2.1'' which comes equipped with one Nvidia P100 GPU, 12 physical cores (OCPU) and 72 GB of RAM. We have tested with distributed training up to 10 GPUs, and found that scalability was close to linear in the tested range. One important lesson learned when using GPUs is, that the slow performance of reading data from OCI storage makes the first training epoch much slower than the rest of the epochs (up to 3-4 times slower). It was therefore very important to use TensorFlow's caching for the training dataset for our tests with GPUs. However, we could only cache the training dataset for tests using 4 nodes or more, given the limited amount of memory in the VM flavor used (72 GB of RAM per node) compared to the size of the training set (200 GB).
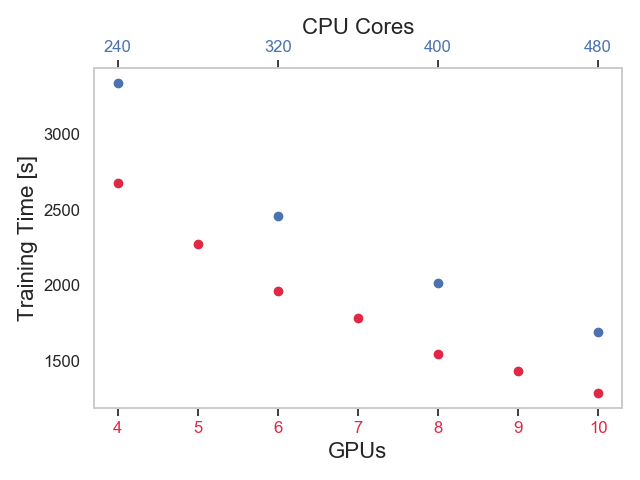
Distributed training tests with CPUs and GPUs were performed using the same infrastructure, namely a Kubernetes cluster built on cloud resources and cloud storage allocated on OCI. Moreover, we used the same script for CPU and GPU training and used the same APIs, tf.distribute and tf.keras, and the same TensorFlow version. The TensorFlow runtime used was different for the two cases, as training on GPU resources took advantage of TensorFlow's optimizations for CUDA and Nvidia GPUs. Figure 3 shows the distributed training time measured for some selected cluster configurations. We can use these results to compare the performance we found when training on GPU and on CPU. For example, we find in Figure 3 that the training time of the Inclusive Classifier for 6 epochs using 400 CPU cores (distributed over 25 VMs equipped with 16 physical cores each) is about 2000 seconds, which is similar to the training time we measured when distributing the training over 6 nodes equipped with GPUs.
When training using GPU resources (Nvidia P100), we measured that each batch is processed in about 59 ms (except for epoch 1 which is I/O bound and is about 3x slower). Each batch contains 128 records, and has a size of about 7.4 MB. This corresponds to a measured throughput of training data flowing through the GPU of about 125 MB/sec per node (i.e. 1.2 GB/sec when training using 10 GPUs). When training on CPU, the measured processing time per batch is about 930 ms, which corresponds to 8 MB/sec per node, and amounts to 716 MB/sec for the training test with 90 workers and 480 CPU cores.
We do not believe these results can be easily generalized to other environments and models, however, they are reported here as they can be useful as an example and for future reference.
Figure 3: Selected measurements of the distributed training time for the Inclusive Classifier model using TensorFlow and tf.distribute with “multi worker mirror strategy”, training for 6 epochs, running on cloud resources, using CPU (2.0 GHz Intel Xeon Platinum 8167M) and GPU (Nvidia P100) nodes, on Oracle's OCI.
TF-Spawner
TF-Spawner is an experimental tool for running TensorFlow distributed training on Kubernetes clusters.
TF-Spawner takes as input the user's Python code for TensorFlow training, which is expected to use
tf.distribute strategy for multi worker training, and runs it on a Kubernetes cluster. TF-Spawner takes care of requesting the desired number of workers, each running in a container image inside a dedicated pod (unit of execution) on a Kubernetes cluster. We used the official TensorFlow images from Docker Hub for this work. Moreover, TF-Spawner handles the distribution of the necessary credentials for authenticating with cloud storage and manages the TF_CONFIG environment variable needed by tf.distribute.
Examples:
TensorBoard metrics visualization:
TensorBoard provides monitoring and instrumentation for TensorFlow operations.
To use TensorBoard with TF-Spawner you can follow a few additional
steps detailed in the documentation.
Figure 4: TensorBoard visualization of the distributed training metrics for the Inclusive Classifier, trained on 10 GPUs nodes on a Kubernetes cluster using TF-Spawner. Measurements show that training convergences smoothly. Note: the reason why we see lower accuracy and greater loss for the training dataset compared to the validation dataset is due to the use of dropout in the model.
Limitations: We found TF-Spawner powerful and easy to use for the scope of this work. However, it is an experimental tool. Notably, there is no validation of the user-provided training script, it is simply passed to Python for execution. Users need to make sure that all the requested pods are effectively running, and have to manually take care of possible failures. At the end of the training, the pods will be found in "Completed" state, users can then manually get the information they need, such as the training time from the pods' log files. Similarly, other common operations, such as fetching the saved trained model, or monitoring training with TensorBoard, will need to be performed manually. These are all relatively easy tasks, but require additional effort and some familiarity with the Kubernetes environment.
Another limitation to the proposed approach is that the use of TF-Spawner does not naturally fit with the use of Jupyter Notebooks, which are often the preferred environment for ML development. Ideas for future work in this direction and other tools that can be helpful in this area are listed in the conclusions.
If you try and find TF-Spawner useful for your work, we welcome feedback.
Conclusions and Acknowledgements
This work shows an example of how we implemented distributed deep learning for a High Energy Physics use case, using commonly used tools and platforms from industry and open source, namely TensorFlow and Kubernetes. A key point of this work is demonstrating the use of cloud resources to scale out distributed training.
Machine learning and deep learning on large amounts of data are standard tools for particle physics, and their use is expected to increase in the HEP community in the coming year, both for data acquisition and for data analysis workflows, notably in the context of the challenges of the
High Luminosity LHC project. Improvements in productivity and cost reduction for development, deployment, and maintenance of machine learning pipelines on HEP data are of high interest.
We have developed and used a simple tool for running TensorFlow distributed training on Kubernetes clusters,
TF-Spawner. Previously reported work has addressed the
implementation of the pipeline and distributed training using Apache Spark. Future work may address the use of other solutions for distributed training, using cloud resources and open source tools, such as Horovod on Spark and KubeFlow. In particular, we are interested in further exploring the integration of distributed training with the analytics platforms based on Jupyter Notebooks.
This work has been developed in the context of the Data Analytics services at CERN and of the
CERN openlab project on machine learning in the cloud in collaboration with Oracle. Additional information on the work described here can be found in the article
Machine Learning Pipelines with Modern Big DataTools for High Energy Physics. The authors would like to thank Matteo Migliorini and Marco Zanetti of the University of Padova for their collaboration and joint work, Thong Nguyen and Maurizio Pierini for their help, suggestions, and for providing the dataset and models for this work. Many thanks also to CERN openlab, to our Oracle contacts for this project, and to our colleagues at the Spark and Hadoop Service at CERN.