This is a performance investigation of Oracle DB and interaction with storage.
Case: DB operations are slow during backup. The system is an OLTP-like workload, IO bound. Most of the reads are via indexes, typically single-block access, not much full scan.The system has still many free CPU cycles.
First analysis: single block read times jump to very high values when backups start.
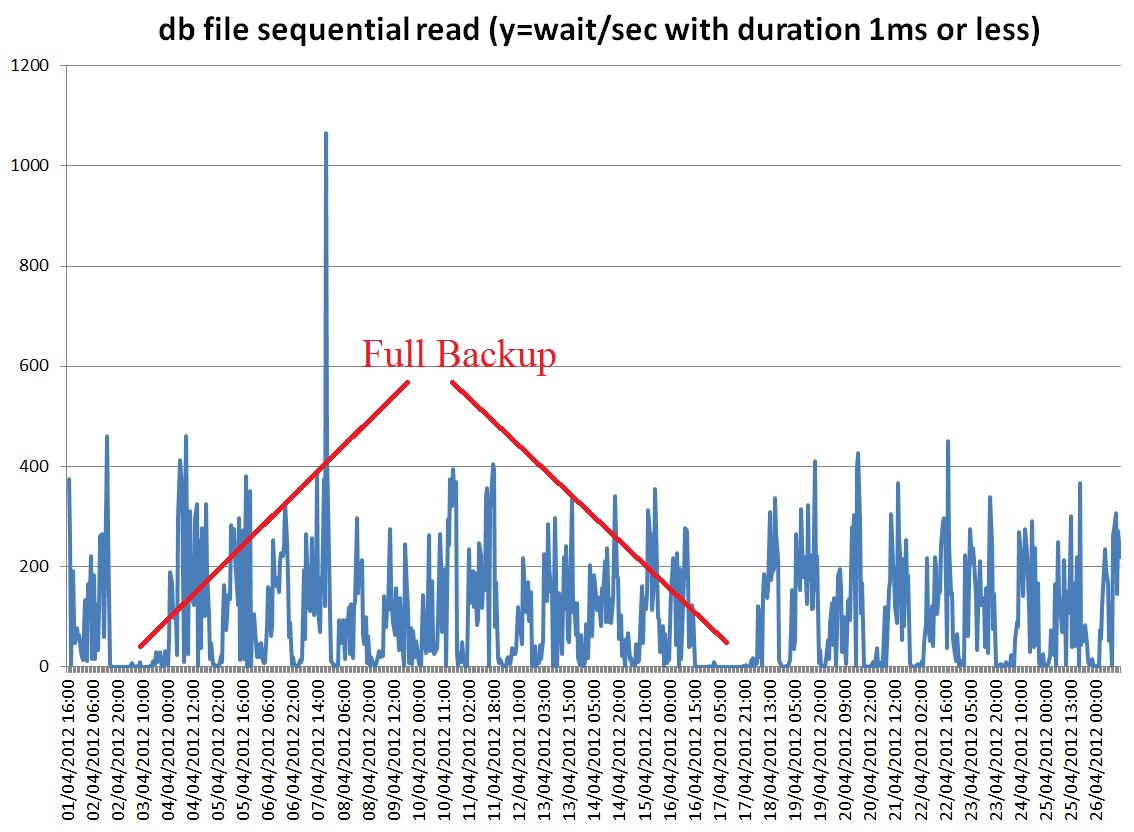
Tools: Use AWR data, to plot db file sequential read wait time over an interval of about 3 weeks. Large spikes can be seen during full DB backup. Spikes are also seen daily when incremental backup starts (see graph below)
Graph: average time spent on db file sequential read events aggregated per hour and plotted as as function of time. High and large spikes of IO latency can be seen during full backups. Smaller spikes during daily incremental backups.
Conclusions from first analysis: Users most important queries are IO latency-bound, latency jumps up during backups, therefore this explains the slowdown seen by the users.
Drill down: We want to understand why IO is slow during backup. Is it some sort of 'interference' of the sequential IO of the backup with random IO of the users? Is it an Oracle problem or a storage problem?
Main idea: use event histogram values reported by Oracle instrumentation to study skew on IO access time and find more about the root cause of the issue.
Investigations: see part 2 of this blog entry.
Techniques and references: To analyze AWR data I have built a set of custom queries against dba_hist_* views and used them inside the excellent
Perfsheet by Tanel Poder.
This is the text of the query used, among others, to generate the graph above:
-- system_event with rate and time
select cast(sn.begin_interval_time as date) beg_time,
ss.dbid,
sn.instance_number,
ss.event_name,
ss.wait_class,
ss.total_waits,
ss.time_waited_micro,
ss.total_waits - lag(ss.total_waits) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first) Delta_waits,
ss.time_waited_micro - lag(ss.time_waited_micro) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first) Delta_timewaited,
extract(hour from END_INTERVAL_TIME-begin_interval_time)*3600
+ extract(minute from END_INTERVAL_TIME-begin_interval_time)* 60
+ extract(second from END_INTERVAL_TIME-begin_interval_time) DeltaT_sec,
round((ss.total_waits - lag(ss.total_waits) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first)) /
(extract(hour from END_INTERVAL_TIME-begin_interval_time)*3600
+ extract(minute from END_INTERVAL_TIME-begin_interval_time)* 60
+ extract(second from END_INTERVAL_TIME-begin_interval_time)),2 ) Waits_per_sec,
round((ss.time_waited_micro - lag(ss.time_waited_micro) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first)) /
(extract(hour from END_INTERVAL_TIME-begin_interval_time)*3600
+ extract(minute from END_INTERVAL_TIME-begin_interval_time)* 60
+ extract(second from END_INTERVAL_TIME-begin_interval_time)),2 ) Rate_timewaited, -- time_waited_microsec/clock_time_sec
round((ss.time_waited_micro - lag(ss.time_waited_micro) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first)) /
nullif(ss.total_waits - lag(ss.total_waits) over (partition by ss.dbid,ss.instance_number,ss.event_id order by sn.snap_id nulls first),0),2) Avg_wait_time_micro
from dba_hist_system_event ss,
dba_hist_snapshot sn
where
%FILTER%
and sn.snap_id = ss.snap_id
and sn.dbid = ss.dbid
and sn.instance_number = ss.instance_number
and sn.begin_interval_time between %FROM_DATE% and %TO_DATE%