Is SELECT COUNT( DISTINCT <col> ) slow?
The answer as it is often the case is 'it depends'. Let's start with an example to get an idea on what are the key variables in this context. I will describe a few simple tests here below using a table called TESTTABLE (see SQL creation scripts later on in this post) of 10M rows, 4GB in size and with 3 columns: a unique numeric ID, a column with row-size 200 bytes and cardinality 10 and another with row-size 200 bytes cardinality 10M. I have cached the table in the buffer cache to simplify the interpretation of the test results. As a reference the sqlplus output here below shows that it takes about 1 second to count the number of rows in the table and that no physical reads are performed while doing so because the table is cached in the buffer cache.SQL> select count(*) from testtable;
COUNT(*)
----------
10000000
Elapsed: 00:00:00.98
Statistics
-------------------------------
526343 consistent gets
0 physical reads
.. ........
0 redo size
Let's now count the NDV (number of distinct values) for the 3 different columns. SELECT COUNT(DISTINCT <col>) from TESTTABLE;
The table here below shows the results rounded to the nearest integer value:
| Column name | Measured NDV | Avg Col Length (bytes) | Elapsed time (sec) |
|---|---|---|---|
| id | 10M | 6 | 11 |
| val_lowcard | 10 | 202 | 6 |
| val_unique | 10M | 208 | 124 |
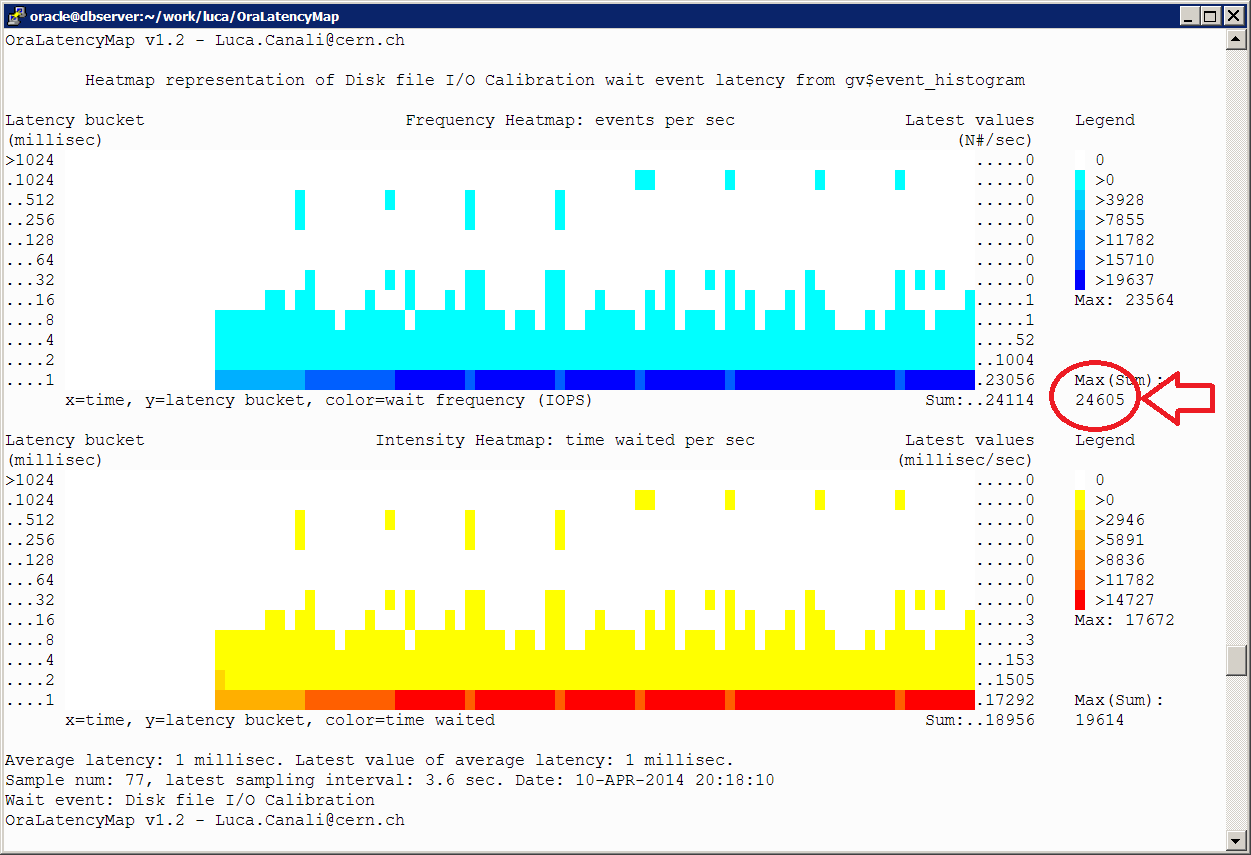
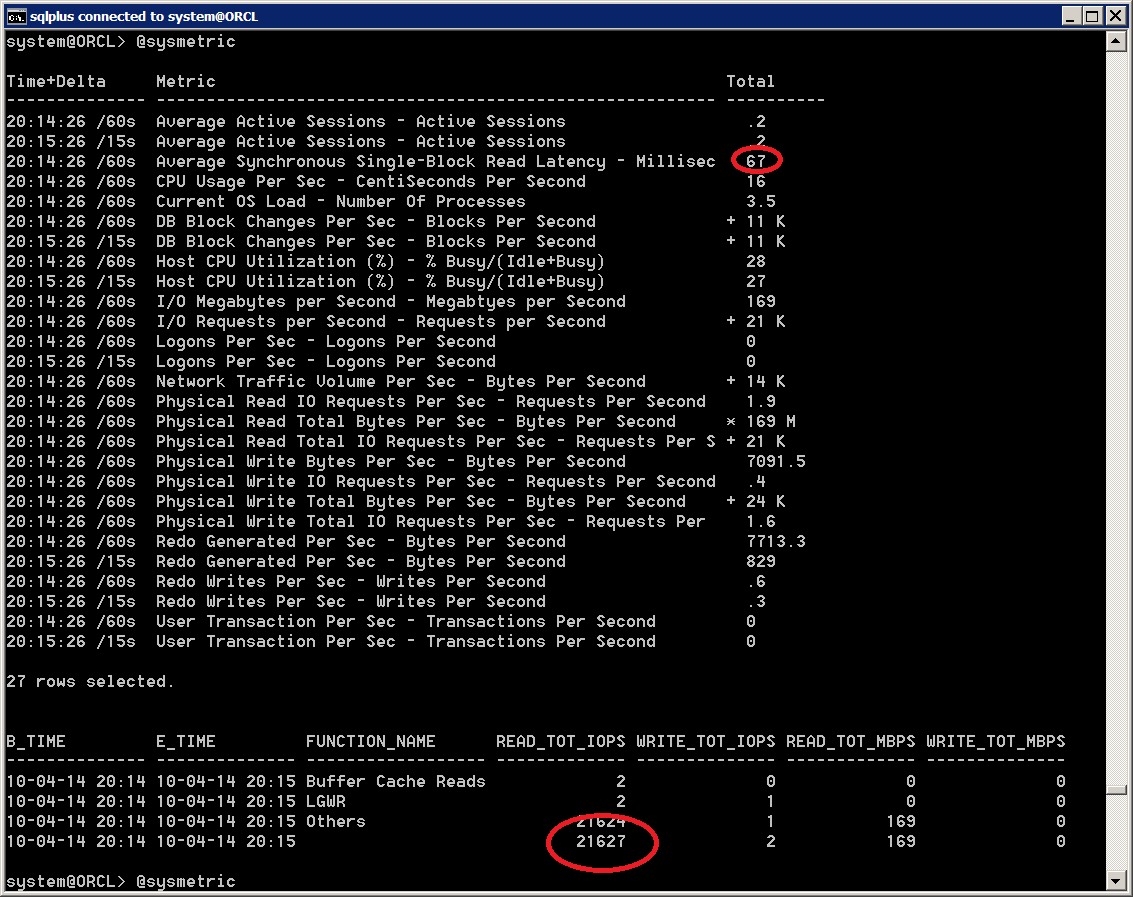
The figure here below shows the execution plan and the tkprof report for the execution with the longest time (NDV calculation for the column VAL_UNIQUE). We can see a pattern emerging. The algorithm used for count distinct needs to use large amounts of memory, therefore also CPU and eventually also processing will spill out the temporary areas and perform I/O operations to and from the temporary tablespace. This is why it can become very slow.

Meet the new algorithm in 12.1.0.2
APPROX_COUNT_DISTINCT is a new function available in Oracle's 12.1.0.2 SQL and is implemented with an algorithm that has low memory footprint and high scalability (more on that later in this post). The other difference with the count distinct legacy approach is that this new function provides estimates of the cardinality as opposed to correct counts, in many cases this would be 'good enough', with the speed difference making up for the lack of precision. Let's see how this new approach performs in the same test system as for the legacy SQL example above. I have run a similar set of tests as in the previous case, the SQL is:SELECT APPROX_COUNT_DISTINCT(<col>) from TESTTABLE;
| Column name | Measured NDV | Avg Col Length (bytes) | Elapsed time (sec) |
|---|---|---|---|
| id | 9705425 | 6 | 2 |
| val_lowcard | 10 | 202 | 5 |
| val_unique | 9971581 | 208 | 6 |
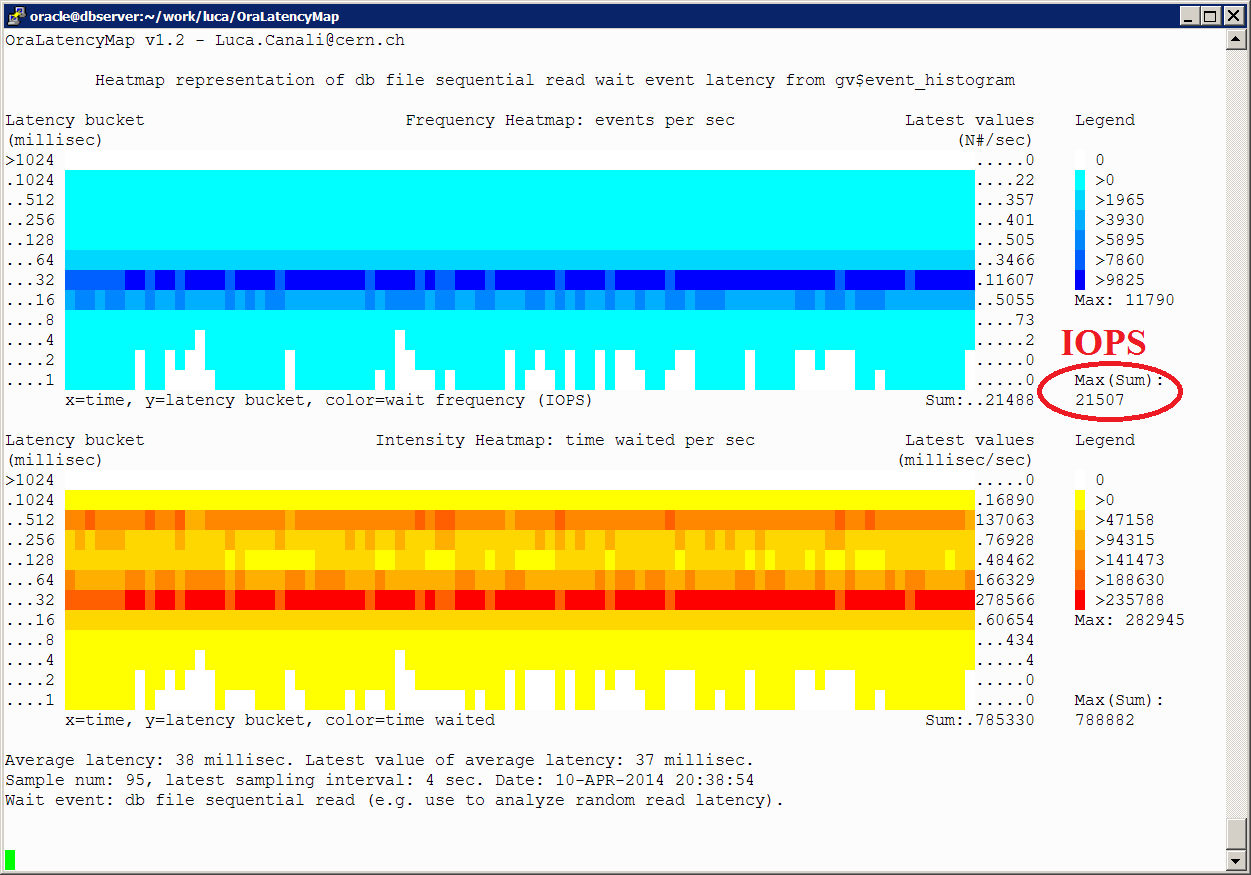
Here below the tkprof report for the execution plan for the case with the longest time (NDV calculation for the column VAL_UNIQUE). We can see that almost all the SQL execution time is accounted as CPU by Oracle and no I/O is performed.

Legacy vs. New
The new algorithm and the legacy approach have similar performance when counting columns of low cardinality, this is illustrated in the example above when counting the column 'val_lowcard' (cardinality 10). In the simple test performed here the new algorithm was marginally faster the the legacy SQL for the low cardinality example, however I can imagine that the opposite may also be true in some cases (this has been reported reported by @jarneil on a different test system where the legacy SQL was waster than APPROX_COUNT_DISTINCT for counting NDV in a low-cardinality case).We expect that the elapsed time needed in the case of low NDV is close to time needed for a full scan of the column being measured, that is the most expensive operation when estimating the cardinality of columns with low NDV is typically to read the column data.
Let's now talk about the more interesting case of large NDV. The case of estimating columns of high cardinality is where the new algorithm shines. As the NDV increases also the 'volume of distinct values' increases, the number of distinct values multiplied by their size increases. As this 'volume of distinct values' get bigger, the legacy algorithm starts to fall behind in performance compared to the new 12.1.0.2 function. This is because the operations requiring sorting/hashing and temporary space start taking more and more resources: first CPU is needed to process the additional memory structures, then also I/O to read and write from the temporary tablespace is needed. This can potentially make the legacy SQL with count distinct orders of magnitude slower than APPROX_COUNT_DISTINCT.
Parallelism
APPROX_COUNT_DISTINCT scales very well by using parallel query. By looking at the execution plan and tkprof report above that should appear clear as the processing is entirely on CPU. Moreover additional details discussed below on the algorithm used by APPROX_COUNT_DISTINCT confirm the scalability of this approach when using parallel query.
The legacy approach instead does not scale very well, in particular when multiple parallel query slaves have to handle a concurrent count distinct while also using TEMP space of the temporary tablespace. In the interest of brevity I will not add here additional details and tests performed for this case.
The legacy approach instead does not scale very well, in particular when multiple parallel query slaves have to handle a concurrent count distinct while also using TEMP space of the temporary tablespace. In the interest of brevity I will not add here additional details and tests performed for this case.
HyperLogLog
I have first learned about the HyperLogLog (HLL) algorithm from Alex Fatkulin's blog and references therein. I find the whole concept quite neat, in particular I enjoy how clever use of math can help in tackling difficult problems when scaling up data processing to very large data sets. The reason I mention it here is that hints that HLL is used can be found by tracing Oracle process execution by stack profiling. For example see the Flame graph below and the annotations of my guess on function name qesandvHllAdd.The flame graph data comes from Linux perf command and the graph itself is generated using Brendan Gregg's FlameGraph tool. More details on this technique of stack profiling applied at investigating Oracle at this blog entry.

Here below are pointers to the commands used for perf data collection and flame graph generation:
# perf -a -g -F 99999 -p <oracle_pid>
# perf script >perf.script
$ cat perf.script|sed -f os_explain.sed| FlameGraph-master/stackcollapse-perf.pl |FlameGraph-master/flamegraph.pl --title "Flamegraph" >Fig1.svg
Conclusions
Oracle 12.1.0.2 makes available to the users a new and fast algorithm for computing cardinality estimates that outperforms the legacy SQL select count(distinct) for most cases of interest. As it is often the case the methods used for investigating the new feature can be more interesting than the actual results Moreover while investigating the new we learn (or re-learn) something important about the old!
The test workload discussed here above in this posts shows also that caching a table into RAM while it is often fast, it does not fix all performance use cases. Caching a table does not necessarily bring all I/O operations to zero, notably because of I/O for TEMP space. This is a well-know fact that appears in several contexts when doing performance tuning, although it may be overlooked at design time. Simplifying for future reference: table caching is not always fast=true.
References
Alex Fatkulin has covered the topic of HyperLogLog in a series very interesting blog posts. Particularly notable the effort to explain in simple terms the HyperLogLog algorithm here.
It is also worth noting that Oracle has introduced in 11g an algorithm for computing NDV restricted to the usage of the DBMS_STATS package. For additional details see Maria Colgan's blog post and Amit Poddar presentation at Hotsos (currently hosted in Jonathan Lewis' blog).
Tuning of Oracle work areas is discussed in Oracle Support Note "How To Super-Size Work Area Memory Size Used By Sessions?" (Doc ID 453540.1). Alex Fatkulin has presented at Hotsos 2014 "Leveraging In-Memory Storage to Overcome Oracle Database PGA Memory Limits".
Test definition scripts
Here below you can find the the statements I used to create the test table for this post's examples. The test system where I ran the examples was configured with 5 GB of db_cache_size (6 GB for the whole SGA), automatic PGA management was used with pga_aggregate_target set to 3 GB. Different memory configurations for the buffer cache and for PGA may produce different test results. In the tests discussed here above, testtable is intended to fit in the buffer cache (and be cached there). Test results for select count distinct have a strong dependence on the size of memory work areas allocated in PGA and the thresholds for spilling to disk (see also the references section above).
No competing/concurrent workload was run during the tests. I have also added some pointers on how I cached the table, note that table caching can be achieved with several alternative methods, such as defining and using a keep cache or by using one of the 2 new methods available in 12.1.0.2: using the in-memory option or the big table caching feature.
create table testtable pctfree 0 cache
tablespace DATA01 nologging
as
select rownum id, to_char(mod(rownum,10))||rpad('mystring',200,'P') val_lowcard, to_char(rownum)||rpad('mystring',200,'P') val_unique
from dba_source,dba_source where rownum<=1e7;
exec dbms_stats.gather_table_stats('SYSTEM','TESTTABLE')
--use this to avoid Oracle's direct reads bypassing the buffer cache
alter session set "_serial_direct_read"=never;
alter system flush buffer_cache;
--make sure that there is enough space in the buffer cache and clean it first
set autotrace on -- allows to measure logical and physical IO
select count(*) from testtable;
select count(*) from testtable; --repeat if needed
References
It is also worth noting that Oracle has introduced in 11g an algorithm for computing NDV restricted to the usage of the DBMS_STATS package. For additional details see Maria Colgan's blog post and Amit Poddar presentation at Hotsos (currently hosted in Jonathan Lewis' blog).
Tuning of Oracle work areas is discussed in Oracle Support Note "How To Super-Size Work Area Memory Size Used By Sessions?" (Doc ID 453540.1). Alex Fatkulin has presented at Hotsos 2014 "Leveraging In-Memory Storage to Overcome Oracle Database PGA Memory Limits".
Test definition scripts
Here below you can find the the statements I used to create the test table for this post's examples. The test system where I ran the examples was configured with 5 GB of db_cache_size (6 GB for the whole SGA), automatic PGA management was used with pga_aggregate_target set to 3 GB. Different memory configurations for the buffer cache and for PGA may produce different test results. In the tests discussed here above, testtable is intended to fit in the buffer cache (and be cached there). Test results for select count distinct have a strong dependence on the size of memory work areas allocated in PGA and the thresholds for spilling to disk (see also the references section above).
No competing/concurrent workload was run during the tests. I have also added some pointers on how I cached the table, note that table caching can be achieved with several alternative methods, such as defining and using a keep cache or by using one of the 2 new methods available in 12.1.0.2: using the in-memory option or the big table caching feature.
No competing/concurrent workload was run during the tests. I have also added some pointers on how I cached the table, note that table caching can be achieved with several alternative methods, such as defining and using a keep cache or by using one of the 2 new methods available in 12.1.0.2: using the in-memory option or the big table caching feature.
create table testtable pctfree 0 cache
tablespace DATA01 nologging
as
select rownum id, to_char(mod(rownum,10))||rpad('mystring',200,'P') val_lowcard, to_char(rownum)||rpad('mystring',200,'P') val_unique
from dba_source,dba_source where rownum<=1e7;
exec dbms_stats.gather_table_stats('SYSTEM','TESTTABLE')
--use this to avoid Oracle's direct reads bypassing the buffer cache
alter session set "_serial_direct_read"=never;
alter session set "_serial_direct_read"=never;
alter system flush buffer_cache;
--make sure that there is enough space in the buffer cache and clean it first
set autotrace on -- allows to measure logical and physical IO
set autotrace on -- allows to measure logical and physical IO
select count(*) from testtable;
select count(*) from testtable; --repeat if needed