Motivations: The techniques and tools described here can be used for performance investigations to complement wait-event based information gathered from the Oracle engine, such as information available with ASH and sql monitoring. They can also be used for complex troubleshooting when the wait interface is failing to instrument a particular problem under study. Last but not least they can be used as a learning aid to investigating Oracle internals.
Context and credits: The use of stack sampling has previously been covered for Oracle investigations by Tanel Poder in several articles (see Tanel's Advanced Oracle Troubleshooting Guide and for example this article).
Brendan Gregg has done original work on the collection and visualization of stack sampled data and by introducing the Flame Graphs visualization technique.
The techniques discussed in this post rely on perf for data collection. Perf is a relatively new addition to the performance tools available for Linux (requires kernel 2.6.31 or higher, for example RHEL6 or OL6). A few additional references on using perf for investigating Oracle are: Frits Hoogland, Kevin Closson, Craig Shallahamer.
This article: In this post we will approach the use of stack sampling with perf and visualization with Flame Graphs by introducing examples of growing complexities and by detailing the steps needed to reproduce the results. The main idea is to give a few hints of what this type of approach can do to help us analyze process execution and performance rather than producing a comprehensive guide.
Example 1: Flame Graph of query execution
In Figure 1 here below we can see a Flame Graph representation of the stack traces collected during the execution of "select count(*) from dba_source" (the details of how the graph was generated are described later in this article).
Figure 1: Flame Graph of "select count(*) from dba_source". See more details for each stack layer by hovering over the graph lines in the SVG version
{kind=link}
The stack traces expose the name of many Oracle's internal functions. There is no public documentation of those internal functions, however much can be guessed by their name and from the documentation in the Oracle Support document "ORA-600 Lookup Error Categories" (formerly MOS note 175982.1, more recently found as an attachment to Note 1321720.1 and also in other links on the internet).
In addition to the support note, Tanel Poder has already done a great job of "decoding" an important class of internal functions, the rowsource functions with prefix qer (query execution rowsource) in his os_explain script. Rowsource functions expose execution plan details, similarly to what is exposed in ASH data (v$active_session_history) at the columns SQL_PLAN_OPERATION and SQL_PLAN_OPTIONS.
Note also that in Flame Graphs the horizontal axis is not time, stack traces are simply pasted by ordering alphabetically (follow this link to Brendan Gregg's article on Flame Graphs).
If we extract only the rowsource entries from the stack trace data represented in Figure 1, we obtain a simplified Flame Graph, which highlights the parts related to query's execution plan: Figure 2. We can recognize there the execution plan operations and how they stack and nest on top of each other. Although SQL is mainly a declarative language here we have a good view of how this is translated at run time into procedural execution: after all the Oracle query engine is just another (complex) C program.

{kind=link}
One subtle, but important point worth repeating is that horizontal axis in the Flame Graph is not time (Brendan Gregg's article on Flame Graphs). However the length of each line in the graph is proportional to the number of captured stack frames, therefore to its execution time. This last sentence may not be valid for a general case but it holds for this example, as the whole query execution time was 'on-CPU' (see more on this later on when we discuss Flame Graphs for I/O-bound workload)

Figure 3: Execution plan and details of the rows processed by each step (Actual Rows, "A-Rows") and logical reads ("Buffers") for the query "select count(*) from dba_source" (Oracle version 11.2.0.3).
How the Flame Graphs of Figure 1 and Figure 2 have been generated
Tools:
- Stack samples have been collected with perf running on RHEL6. This example will not work on old kernel, notably it will not work on RHEL5. Perf has been run as the root user on the DB server.
- Flame Graphs have been generated using https://github.com/brendangregg/FlameGraph. You can download the latest version from that link for example as a zip (or clone the project locally using "git clone").
- Download os_explain and edit out the string replacement part in a file called os_explain.sed. Here below an example of these steps:

- Session1: run sqlplus and find the os pid of its server process. For example use this SQL: select spid from v$process where addr in (select paddr from v$session where audsid =sys_context('USERENV','SESSIONID'));
- Session1: run the test SQL to load data into the cache, for this example run: select count(*) from dba_source;
- Session 2: on a different window as root start recording the stack traces. As the execution is very short in duration we can afford high frequency sampling (100KHz). Example: perf record -a -g -F100000 -p <pid of sqlplus process>
- Session 1: run the sql under study, in this example: select count(*) from dba_source;
- Session 2: CTRL-C to stop recording
Steps for data processing and visualization:
- Generate the stack trace in a txt file: perf script >myperf_script.txt
- Create the flame graph: grep -v 'cycles:' myperf_script.txt|sed -f os_explain.sed|../FlameGraph-master/stackcollapse-perf.pl |../FlameGraph-master/flamegraph.pl --title "Flame Graph: select count(*) from dba_source" >Figure1.svg
- Create the flame graph with only rowsources: grep -i -e qer -e opifch -e ^$ test_perf_script23.txt|sed -f os_explain.sed|../FlameGraph-master/stackcollapse-perf.pl|../FlameGraph-master/flamegraph.pl --title "Flame Graph Rowsource: select count(*) from dba_source" >Figure2.svg
Example 2: profiling multiple processes - logical IO
In this example we trace CPU workload running from multiple sessions and generate on-CPU Flame Graphs. We use SLOB for logical IO testing to generate the CPU-bound workload, that is SLOB queries run with their entire data set in the buffer cache in this example.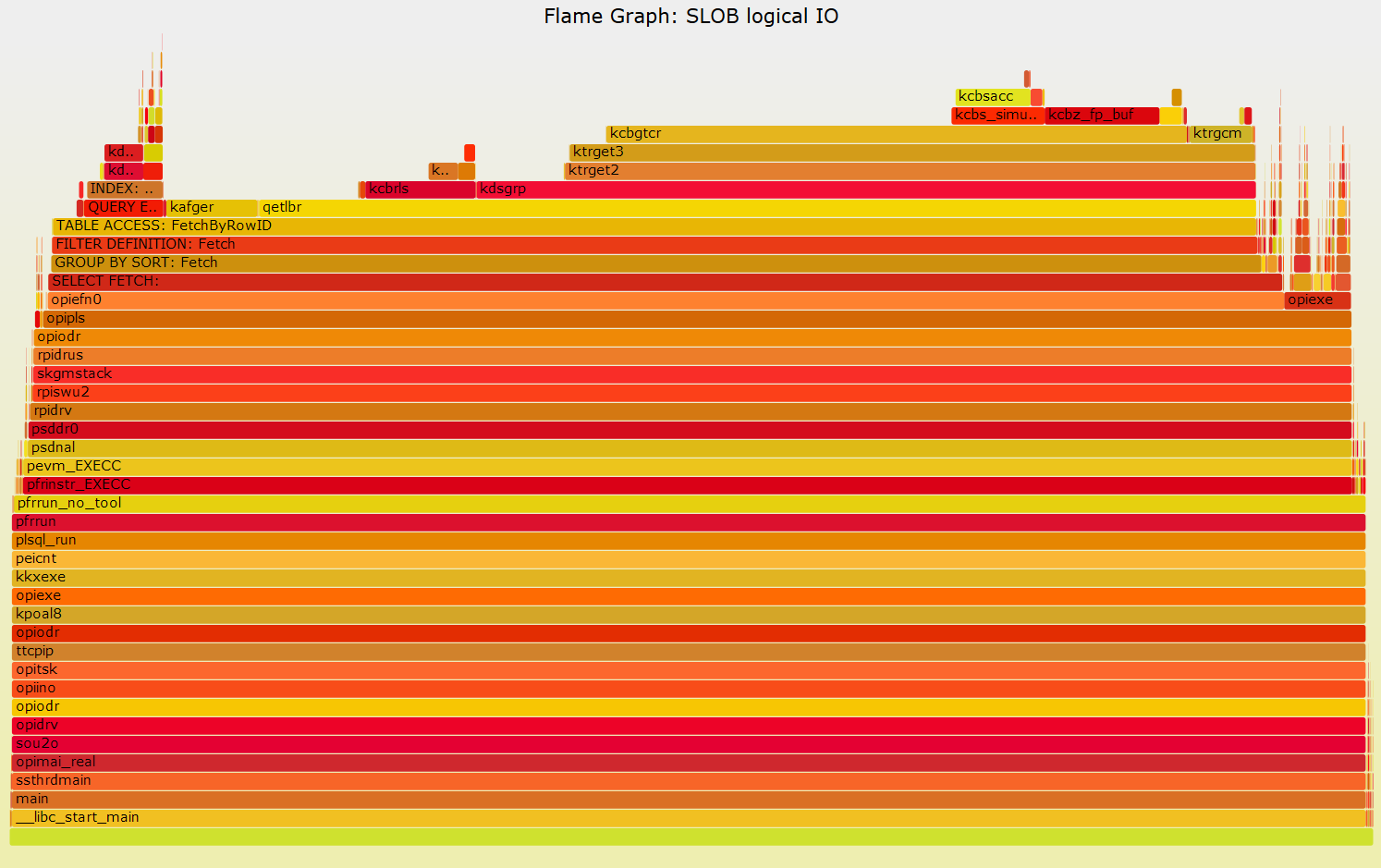
{kind=link}
Similarly to what we discussed in the Example 1 above, we can now filter the stack traces to highlight the rowsource data. In addition in this example we also leave the details of the functions that start with the letter 'k', notably this includes the Oracle kernel function kcbgtcr (Kernel Cache Buffer Get Consistent Read).
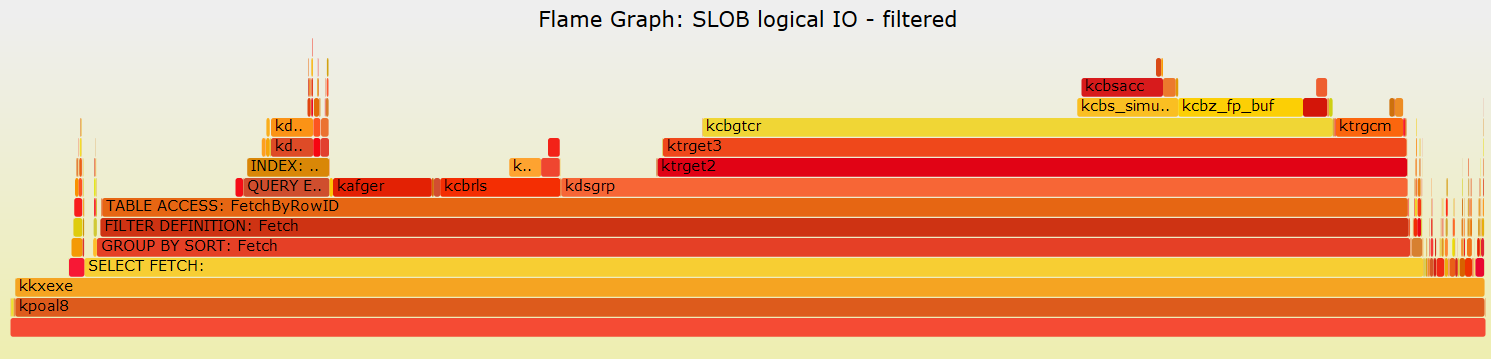
{kind=link}
We can correlate the rowsource execution steps as we see them in in Figure 5 with the execution plan of the SLOB test query reported here below (Figure 6).

How the Flame Graphs 4 and 5 have been generated
Test setup:
- See example 1 above on the details about downloading the FlameGraph scripts and about the requirements for perf and os_explain.sed
- Download SLOB and configure the test environment. 8 schemas have been used for the tests reported here. See also this post for additional details on testing with SLOB.
- Make sure that SLOB runs with all data in buffer cache. 8 schemas of 1M blocks each have been used for this tests and a buffer cache of 70 GB.
- To facilitate loading data into the buffer cache this SQL was run prior to testing:
- alter session set "_serial_direct_read"=never;
- alter table user1.cf1 cache;
- select count(*) from user1.cf1;
- repeat for the rest of the test users.
- while a SLOB test is running we can check that the workload is not doing physical IO for example using Tanel's snapper. For example: snapper all 10 1 "select inst_id, sid from gv$session where username like 'USER%'"
Test execution:
- Session 1: run the SLOB test. In the test case described here below I used 8 sessions (that is I started the test with ./runit.sh 8)
- Session1: identify the PIDs of the server sessions running SLOB workload. For example use: select spid from v$process where addr in (select paddr from v$session where username like 'USER%');
- Session 2: gather perf data for 20 seconds at default sampling rate (1 KHz): perf record -g -a -p 51929,51930,51931,51932,51933,51934,51962,51963 sleep 20
Data processing and visualization:
- Generate the stack trace in a txt file: perf script >myperf_scriptSLOB.txt
- Create the flame graph: grep -v 'cycles:' myperf_scriptSLOB.txt|sed -f os_explain.sed|../FlameGraph-master/stackcollapse-perf.pl|../FlameGraph-master/flamegraph.pl --title "Flame Graph: SLOB physical IO" >Figure1_SLOB.svg
- Create the flame graph with only rowsource steps and k* function: grep -i -e qer -e opifch -e ' k' -e ^$ myperf_scriptSLOB.txt|sed -f os_explain.sed|../FlameGraph-master/stackcollapse-perf.pl|../FlameGraph-master/flamegraph.pl --title "Flame Graph: SLOB physical IO - filtered" >Figure2_SLOB.svg
Example 3: profiling multiple processes - physical IO
We will use the same SLOB workload as example 2 but this time with a very small buffer cache therefore forcing the DB to do physical I/O to read SLOB data from the storage. Random I/O reads will be instrumented by Oracle with the db file sequential read wait event (see also this post for additional details and examples on testing random I/O with SLOB).

Figure 7: Flame Graph of SLOB physical IO (8 concurrent sessions). See more details in the SVG version
{kind=link}
By comparing Figure 7 (SLOB physical I/O) with Figure 4 (SLOB logical I/O) we notice that
- we have many more function calls in the case of physical I/O than in the corresponding graph with only logical I/O. Moreover in Figure 7 we can see several stack traces that contain only OS kernel calls and that cannot be easily associated with a particular step in Oracle execution. Note the system under tests used NAS storage so physical IO appears as network traffic.
- Moreover from the SVG graph versions we can count the number of samples stack traces and notice that in the case of physical IO we have considerably less values. This is because perf will only collect stack traces when the process is on-CPU.
- Another important fact that we notice is the appearing of Oracle kernel kcbzib function. This seems to be associated with reading blocks into the cache with physical reads.

{kind=link}
Example 4: profiling the server workload
This example is about measuring and visualizing stack traces collected for on entire server. The interpretation becomes more complex as multiple workloads are measured together. Moreover system calls for I/O and other activities are measured as well.Another important fact to take into consideration is the footprint of data collection. For this reason a reduced frequency of 99 HZ was used for sampling.
Data gathering at 99HZ for 20 seconds for the whole instance: perf record -g -a -F99 sleep 20
The steps for data visualization are the same as was used in Examples 2 and 3. Here below in Figure 9 the Flame Graph of the measured data and a 'filtered version' in Figure 10.
- Generate the stack trace in a txt file: perf script >perf_data.txt
- The commands used to generate the 'filtered' Figure 10 are: grep -i -e qer -e opifch -e ' k' -e exe -e ^$ perf_data.txt|sed -f os_explain.sed|../FlameGraph-master/stackcollapse-perf.pl|../FlameGraph-master/flamegraph.pl --title "Flame Graph - filtered" >perf_Figure10.svg
From the row source names reported in Figure 10 below we can guess what the workload on the server was, which types of operations were executed, with details on the queries, such as the access path used and on the type of DML. We can also measure which Oracle functions were executed for most of the CPU time. It's worth mentioning again that only on-CPU workload was captured.

{kind=link}

{kind=link}
Conclusions
High-frequency sampling stack traces is a powerful technique to investigate process execution at the OS level, in particular for CPU-bound processes. This technique can be successfully applied to the study of Oracle performance and complex troubleshooting. It can complement and in some cases supplement the information exposed by Oracle's V$ views and wait event interface in general. Flame graphs are a visualization technique introduced by Brendan Gregg to facilitate the analysis of sampled stack data. The analysis of stack traces for Oracle processes currently relies on the little information available on the Oracle Support document "ORA-600 Lookup Error Categories" (formerly MOS note 175982.1, more recently seen with note 1321720.1) and on the published work of experts who have approached this field and published their findings, notably Tanel Poder.Much of the potential of these techniques is still untapped, we have covered in this article a few basic examples.
Additional resources on interpreting stack traces and on profiling Oracle rowsources and SQL execution can be found in Tanel's blog and Enkitec TV video and in Alexander Anokhin's blog.
More info on the use of Flame Graphs can be found in Brendan Gregg's blog.
See also on this blog a post about using Flame Graphs for investigating Oracle optimizer.
No comments:
Post a Comment