Introduction to Spark performance instrumentation
Before discussing custom development and tools in the next paragraphs, I want to cover some of the common and most basic approaches to measuring performance with Spark. Elapsed time is probably the first and easiest metric one can measure: you just need to instrument your code with time measurements at the beginning and end of the code you want to measure. For example you can do this by calling System.nanoTime (Scala) or time.time() (Python). When using Spark with Scala, a way to execute code and measure its elapsed time is by using: spark.time(<code to measure>), for example:
scala> spark.time(sql("select count(*) from range(1e4) cross join range(1e4)").show)
+---------+
| count(1)|
+---------+
|100000000|
+---------+
Time taken: 1157 ms
The problem with investigating performance by just measuring elapsed time is that this approach often does not provide insights on why the system performs in a certain way. Many are familiar with a related pitfall that comes from using "black box" benchmark workloads. It is often found that the results of a benchmark based on measuring latency of a reference workload do not generalize well to production use cases. Typically you need to fig to the root cause analysis and find what is happening behind the hood. This is valid in general when doing performance investigations/drill-down, in this post we apply these ideas to Spark investigations.
The Spark WebUI is the next obvious place to go to for additional information and measurements when troubleshooting, or just monitoring job execution. For those of you knew to Spark, the WebUI is normally accessible by pointing your browser to port 4040 of the driver node. The WebUI is OK for interactive troubleshooting , however it lacks flexibility for performing custom aggregations and metrics visualizations, among others. The next stop is Spark's REST API (see also Spark documentation "Monitoring and Instrumentation"), which makes the information available from the WebUI available through a REST interface. This opens the possibility to write custom analysis on the captured metrics. Moreover the API exposes a list of metrics, including CPU usage that in some cases go beyond what is exposed from the web pages of the WebUI (as of Spark version 2.1.0).For completeness I want to mention also Spark's metrics system that can be used to send metrics' data to several sinks, including Graphite, to monitoring purposes.
Note: if you are new to Spark before reading further I advise to get an overview of Spark execution model (see for example "Job Scheduling") and make sure you have a practical understanding of what Jobs, Stages and Tasks are.
A practical introduction to Spark Listeners
For the scope of this post you just need to know that listeners are implemented as Scala classes and used by the Spark engine to "trigger" code execution on particular events, notably one can use the listeners to collect metrics information at each job/stage/task start and end events. There is more to it than this simple explanation, but this should be enough to help you understanding the following examples if you are new to these topic (see the references section of this post for additional links to more detailed explanations).
1. A basic example that you can test using spark-shell (the Scala REPL for Spark) should help illustrating how the instrumentation with listeners work (see this Github gist):
What can you get with this simple example of the instrumentation is the executor run time and CPU time, aggregated by Stage. For example when running the simple SQL with a cartesian join used in the example of the previous paragraph, you should find that the CustomListener emits log warning messages with workload metrics information similar to the following:
WARN CustomListener: Stage completed, runTime: 8, cpuTime: 5058939
WARN CustomListener: Stage completed, runTime: 8157, cpuTime: 7715929885
WARN CustomListener: Stage completed, runTime: 1, cpuTime: 1011061
Note that "run time" is measured in milliseconds, while "CPU time " is measured in nanoseconds. The purpose of the example is to illustrate that you can get interesting metrics from Spark execution using custom listeners. There are more metrics available, they are exposed to the code in the custom listener via the stageInfo.taskMetrics class. This is just a first step, you will see more in the following. As a recap, the proof-of-concept code of this basic example:
- creates the class CustomListener extending SparkListener
- defines a method that overerides onStageCompleted to collect the metrics at the end of each stage
- instantiates the class and "attaches it" to the active Spark Context using sc.addSparkListener(myListener)
2. Dig deeper into how the Spark Listeners work by cloning a listener from the WebUI and then examine the metrics values from the cloned object. This is how you can do it from the spark-shell command line:
scala> val myConf = new org.apache.spark.SparkConf()
scala> val myListener = new org.apache.spark.ui.jobs.JobProgressListener(myConf)
scala> sc.addSparkListener(myListener)
myListener.completedStages.foreach(si => (
println("runTime: " + si.taskMetrics.executorRunTime +
", cpuTime: " + si.taskMetrics.executorCpuTime)))
- Spark listeners are used to implement monitoring and instrumentation in Spark.
- This provides a programmatic interface to collect metrics from Spark job/stage/task executions.
- User programs can extend listeners and gather monitoring information.
- Metrics are provided by the Spark execution engine at for each task. Metrics are also provided in aggregated form at higher levels, notably at the stage level.
- One of the key structures providing metrics data is the TaskMetrics class that reports for example run time, CPU time, shuffle metrics, I/O metrics and others.
Key learning point: it is possible to attach a listener to an active Spark Context, using: sc.addSparkListener).
For completeness, there is another method to attach listeners to Spark Context using --conf spark.extraListeners, this will be discussed later in this post.
It's time to write some code: sparkMeasure
Some of the key features of sparkMeasure are:
- the tool can be used to collect Spark metrics data both from Scala and Python
- the user can choose to collect data (a) aggregated at the end of each Stage of execution and/or (b) performance metrics data for each Task
- data collected by sparkMeasure can be exported to a Spark DataFrame for workload exploration and/or can saved for further analysis
- sparkMeasure can also be used in "Flight Recorder" mode, recording all metrics in a file for later processing.
- To use sparkMeasure, download the jar or point to its coordinates on Maven Central as in this example: bin/spark-shell --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11
- Another option is to compile and package the jar using sbt.
- run spark-shell/pyspark/spark-submit adding the packaged jar to the "--jars" command line option. Example: spark-shell --jars target/scala-2.11/spark-measure_2.11-0.12-SNAPSHOT.jar
Examples of usage of sparkMeasure
Note this requires sparkMeasure, packaged in a jar file as detailed above:
[bash]$ spark-shell --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11
This will instantiate the instrumentation, run the test workload and print a short report:
scala> val stageMetrics = new ch.cern.sparkmeasure.StageMetrics(spark)
scala> stageMetrics.runAndMeasure(sql("select count(*) from range(1e4) cross join range(1e4)").show)
Scheduling mode = FIFO
Spark Contex default degree of parallelism = 8
Aggregated Spark stage metrics:
numstages = 3
sum(numtasks) = 17
elapsedtime = 1092 (1 s)
sum(stageduration) = 1051 (1 s)
sum(executorruntime) = 7861 (8 s)
sum(executorcputime) = 7647 (8 s)
sum(executordeserializetime) = 68 (68 ms)
sum(executordeserializecputime) = 22 (22 ms)
sum(resultserializationtime) = 0 (0 ms)
....
Note: additional metrics reported by the tool are omitted here as their value is close to 0 are negligible for this example
The first conclusion is that the job executes almost entirely on CPU, not causing any significant activity of shuffle and/or disk read/write, as expected. You can see in the printed report that the job was executed with 3 stages and that the default degree of parallelism was set to 8. Executor run time and CPU time metrics, both report cumulative time values and are expected to be greater than the elapsed time: indeed their value is close to 8 (degree of parallelism) * elapsed (wall clock) time.
A note on what happens with stageMetrics.runAndMeasure:
- the stageMetrics class works as "wrapper code" to instantiate an instance of the custom listener "StageInfoRecorderListener"
- it adds the listener into the active Spark Context, this takes care of recording workload metrics at each Stage end event,
- finally when the execution of the code (an SQL statement in this case) is finished, runAndMeasure exports the metrics into a Spark DataFrame and prints a cumulative report of the metrics collected.
Example 1b: This is the Python equivalent of the example 1a above (i.e. relevant when using pyspark). The example code is:
$ pyspark --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11
stageMetrics = sc._jvm.ch.cern.sparkmeasure.StageMetrics(spark._jsparkSession)
stageMetrics.begin()
spark.sql("select count(*) from range(1e4) cross join range(1e4)").show()
stageMetrics.end()
stageMetrics.printReport()
Note that the syntax for the Python example is almost the same as for the Scala example 1a, with the notable exceptions of using sc_jvm to access the JVM from Python, and the use of spark._jsparkSession to access the relevant Spark Session. Another difference between Scala and Python, is that the method stageMetrics.runAndMeasure used in example 1a does not work in Python, you will need to break down its operations (time measurement and reporting of the results) as detailed in the example 1b.
$ spark-shell --num-executors 14 --executor-cores 4 --driver-memory 2g --executor-memory 2g --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11
The test workload for this example is the one previously described in the post "Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs". This is the code for preparing the test tables:
val testNumRows = 1e7.toLong
sql(s"select id from range($testNumRows)").createOrReplaceTempView("t0")
sql("select id, floor(200*rand()) bucket, floor(1000*rand()) val1, floor(10*rand()) val2 from t0").cache().createOrReplaceTempView("t1")
sql("select count(*) from t1").show
This part instantiates the classe used to measure Task metrics using custom listeners:
val taskMetrics = new ch.cern.sparkmeasure.TaskMetrics(spark)
This is the code to run the test workload:
taskMetrics.runAndMeasure(sql(
"select a.bucket, sum(a.val2) tot from t1 a, t1 b where a.bucket=b.bucket and a.val1+b.val1<1000 group by a.bucket order by a.bucket").show)
The metrics values collected and aggregated over all the tasks underlying the Spark workload under measurement (one SQL statement execution in this case) are:
Scheduling mode = FIFO
Spark Contex default degree of parallelism = 56
Aggregated Spark task metrics:
numtasks = 312
elapsedtime = 341393 (5.7 min)
sum(duration) = 10397845 (2.9 h)
sum(schedulerdelay) = 3737
sum(executorruntime) = 10353312 (2.9 h)
sum(executorcputime) = 10190371 (2.9 h)
sum(executordeserializetime) = 40691 (40 s)
sum(executordeserializecputime) = 8200 (8 s)
sum(resultserializationtime) = 105 (0.1 s)
sum(jvmgctime) = 21524 (21 s)
sum(shufflefetchwaittime) = 121732 (122 s)
sum(shufflewritetime) = 13101 (13 s)
sum(gettingresulttime) = 0 (0 ms)
max(resultsize) = 6305
sum(numupdatedblockstatuses) = 76
sum(diskbytesspilled) = 0
sum(memorybytesspilled) = 0
max(peakexecutionmemory) = 42467328
sum(recordsread) = 1120
sum(bytesread) = 74702928 (74.7 MB)
sum(recordswritten) = 0
sum(byteswritten) = 0
sum(shuffletotalbytesread) = 171852053 (171.8 MB)
sum(shuffletotalblocksfetched) = 13888
sum(shufflelocalblocksfetched) = 1076
sum(shuffleremoteblocksfetched) = 12812
sum(shufflebyteswritten) = 171852053 (171.8 MB)
sum(shufflerecordswritten) = 20769230
Spark Contex default degree of parallelism = 56
Aggregated Spark task metrics:
numtasks = 312
elapsedtime = 341393 (5.7 min)
sum(duration) = 10397845 (2.9 h)
sum(schedulerdelay) = 3737
sum(executorruntime) = 10353312 (2.9 h)
sum(executorcputime) = 10190371 (2.9 h)
sum(executordeserializetime) = 40691 (40 s)
sum(executordeserializecputime) = 8200 (8 s)
sum(resultserializationtime) = 105 (0.1 s)
sum(jvmgctime) = 21524 (21 s)
sum(shufflefetchwaittime) = 121732 (122 s)
sum(shufflewritetime) = 13101 (13 s)
sum(gettingresulttime) = 0 (0 ms)
max(resultsize) = 6305
sum(numupdatedblockstatuses) = 76
sum(diskbytesspilled) = 0
sum(memorybytesspilled) = 0
max(peakexecutionmemory) = 42467328
sum(recordsread) = 1120
sum(bytesread) = 74702928 (74.7 MB)
sum(recordswritten) = 0
sum(byteswritten) = 0
sum(shuffletotalbytesread) = 171852053 (171.8 MB)
sum(shuffletotalblocksfetched) = 13888
sum(shufflelocalblocksfetched) = 1076
sum(shuffleremoteblocksfetched) = 12812
sum(shufflebyteswritten) = 171852053 (171.8 MB)
sum(shufflerecordswritten) = 20769230
The main points to note from the output of the aggregated metrics are:
- The workload/SQL execution takes about 5 minutes of elapsed time (wall-clock time, as observed by the user launching the query).
- The workload is CPU-bound: the reported values for "run time" and "CPU time" metrics are almost equal, moreover the reported values of other time-related metrics are close to 0 and negligible for this workload. This behavior was expected from the results of the analysis discussed at this link
- The total time spent executing the SQL summing the time spent by all the tasks is about 3 hours.
- The amount of CPU "cores" used concurrently, on average over the elapsed time of the SQL execution, can be estimated with this formula: sum(executorcputime) / elapsedtime = 10190371 / 341393 ~ 30
- The number of allocated cores by Spark executors is 56 (see also the reported value of default parallelism). Compare the 56 allocated cores to the calculated average CPU core utilization of 30. This points to the fact that the allocated CPUs were not fully utilized on average and it's worth additional investigations (more about this in the following)
Workload metrics show that the execution was CPU-bound but also that not all the potentially available CPU cycles on the executors were used. Why the low efficiency? The idea is to drill down on this performance-related question using the metrics collected by the TaskMetrics class and TaskInfoRecorderListener, which detail the behavior of each executed task. As a reference, the following piece of code can be used to export all the collected metrics into a DataFrame and also to save them to a file for further analysis:
// export task metrics information into a Spark DataFrame for analysis
// if needed, also save them to disk
// if needed, also save them to disk
val df = taskMetrics.createTaskMetricsDF()
taskMetrics.saveData(df, "myPerfTaskMetrics1")
Note: It is also useful to note the start and end time of the execution of the code of interest. When using taskMetrics.runAndMeasure those values can be retrieve by printing taskMetrics.beginSnapshot and taskMetrics.endSnapshot, another option is to run System.currentTimeMillis() at the start and end of the workload of interest
The plot of the "Number of running Spark tasks vs. Time" (see below) can give you more clues on why the allocated CPUs were not fully ustilized during the workload execution. You can see that (1) in the first 150 seconds of the workload execution, the system uses all the available cores, after that it starts to slowly "ramp down", finally an important amount of time is spent on a long tail with some "straggler tasks". This provides additional information on why and how the SQL query under study was not able to use all the available CPUs all the time, as discussed above: we find that some of the available CPUs were idle for a considerable amount of time. It is worth reminding that this particular workload is CPU bound (i.e. no significant time is spent on I/O or other activities). For the pourpose of this post we can stop the analysis here. You can find the code for this analysis, with plots and additional drill down on the collected metrics in the notebook at this link
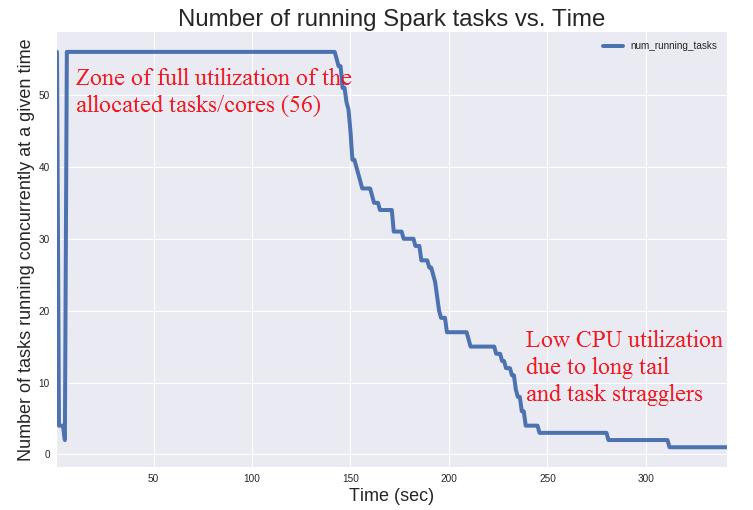
The plot of the "Number of running Spark tasks vs. Time" (see below) can give you more clues on why the allocated CPUs were not fully ustilized during the workload execution. You can see that (1) in the first 150 seconds of the workload execution, the system uses all the available cores, after that it starts to slowly "ramp down", finally an important amount of time is spent on a long tail with some "straggler tasks". This provides additional information on why and how the SQL query under study was not able to use all the available CPUs all the time, as discussed above: we find that some of the available CPUs were idle for a considerable amount of time. It is worth reminding that this particular workload is CPU bound (i.e. no significant time is spent on I/O or other activities). For the pourpose of this post we can stop the analysis here. You can find the code for this analysis, with plots and additional drill down on the collected metrics in the notebook at this link
Why is this useful: Performing analysis of the workload by drilling down into the metrics collected at the task level is of great help to understand why a given workload performs in a certain way and to identify the bottlenecks. The goal is also to derive actionable information to further improve the performance. You may be already familiar with investigating Spark performance using the Event Timeline in the Spark WebUI, which already makes this type of investigations possible.
The techniques discussed in this post allow to extend and generalize the analysis, the idea is that you can export all the available metrics to your favorite analytics tool (for example a Jupyter notebook running PySpark) and experiment by aggregating and filtering metrics across multiple dimensions. Moreover the analysis can span multiple stages or jobs as needed and can correlate the behavior of all the collected metrics, as relevant (elapsed time, CPU, scheduler delay, shuffle I/O time, I/O time, etc). Another point is that having the metrics stored on a file allows to compare jobs performance across systems and/or application releases in a simple way and opens also the way to automation of data analysis tasks
The techniques discussed in this post allow to extend and generalize the analysis, the idea is that you can export all the available metrics to your favorite analytics tool (for example a Jupyter notebook running PySpark) and experiment by aggregating and filtering metrics across multiple dimensions. Moreover the analysis can span multiple stages or jobs as needed and can correlate the behavior of all the collected metrics, as relevant (elapsed time, CPU, scheduler delay, shuffle I/O time, I/O time, etc). Another point is that having the metrics stored on a file allows to compare jobs performance across systems and/or application releases in a simple way and opens also the way to automation of data analysis tasks
Example 3: This example is about measuring a complex query taken from the TPCS-DS benchmark at scale 1500GB deployed using spark-sql-perf. The query tested is TPCDS_v1.4_query 14a. The amount of I/O and of shuffle to support the join operations in this query are quite important. In this example Spark was run using 14 executors (on a cluster) and a total of 28 cores (2 cores for executor). Spark version: 2.1.0. The example is reported mostly to show that sparkMeasure can be used also for complex and long-running workload. I postpone the analysis, as that would go beyond the scope of this post. The output metrics of the execution of query TPCDS 14a in the test environment described above are:
SparkContex default degree of parallelism = 28
numstages = 23
sum(numtasks) = 13580
sum(duration) = 6136302 (1.7 h)
sum(executorruntime) = 54329000 (15.1 h)
sum(executorcputime) = 36956091 (10.3 h)
sum(executordeserializetime) = 52272 (52 s)
sum(executordeserializecputime) = 28390 (28 s)
sum(resultserializationtime) = 757 (0.8 s)
sum(jvmgctime) = 2774103 (46 min)
sum(shufflefetchwaittime) = 6802271 (1.9 h)
sum(shufflewritetime) = 4074881 (1.1 h)
max(resultsize) = 12327247
sum(numupdatedblockstatuses) = 894
sum(diskbytesspilled) = 0
sum(memorybytesspilled) = 1438044651520 (1438.0 GB)
max(peakexecutionmemory) = 379253665280
sum(recordsread) = 22063697280
sum(bytesread) = 446514239001 (446.5 GB)
sum(recordswritten) = 0
sum(byteswritten) = 0
sum(shuffletotalbytesread) = 845480329356 (845.5 GB)
sum(shuffletotalblocksfetched) = 1429271
sum(shufflelocalblocksfetched) = 104503
sum(shuffleremoteblocksfetched) = 1324768
sum(shufflebyteswritten) = 845478036776 (845.5 GB)
sum(shufflerecordswritten) = 11751384039
The flight recorder mode for sparkMeasure
For example using the spark-submit command line you can do that by adding: "--conf spark.extraListeners=...". The code for two listeners suitable for "Flight Mode" is provided with sparkMeasure: FlightRecorderStageMetrics and FlightRecorderTaskMetrics, respectively to measure stage- and task-level metrics. Example:
$ spark-submit --conf spark.extraListeners=ch.cern.sparkmeasure.FlightRecorderStageMetrics --packages ch.cern.sparkmeasure:spark-measure_2.11:0.11 ...additional jars and/or code
The flight recorder mode will save the results in serialized format on a file in the driver's filesystem. The action of saving the metrics to a file happens at the end of the application and is triggered by intercepting the relative event using the listener. Additional parameters are available to specify the name of the output files:
--conf spark.executorEnv.taskMetricsFileName=<file path> (defaults to "/tmp/taskMetrics.serialized")
--conf spark.executorEnv.stageMetricsFileName=<file path> (defaults to "/tmp/stageMetrics.serialized")
You will need to post-process the output files produced by the "Flight Recorder" mode. The reason is that the saved files contain the collected metrics in the form of serialized objects. You can read the files and deserialize the objects using the package Utils provided in sparkMeasure. After deserialization the values are stored in a ListBuffer that can be easily transformed in a DataFrame. An example of what all this means in practice:
val taskVals = ch.cern.sparkmeasure.Utils.readSerializedTaskMetrics("<file name>")
val taskMetricsDF = taskVals.toDF
Similarly, when post-processing stage metrics:
val stageVals = ch.cern.sparkmeasure.Utils.readSerializedStageMetrics("<file name>")
val stageMetricsDF = stageVals.toDF
Recap and main points on how and why to use sparkMeasure
- Use sparkMeasureto measure Spark workload performance. Compile and add the jar of sparkMeasure to your Spark environemnt
- Consider sparkMeasure as an alternative and extension of spark.time(<spark code>), instead just measuring the elapsed time with stageMetrics.runAndMeasure(<spark code>) or taskMetrics.runAndMeasure(<spark code>) you have the summary of multiple workload metrics
- Start with measuring at Stage level, as it is more lightweight. Use the Task-level metrics if you need to drill down on task execution details or skew (certain tasks or hosts may behave differtly than the average)
- Export metrics for offline analysis if needed and import them in your tool of choice (for example a notebook environment).
Summary and further work
Collecting and analyzing workload metrics beyond simple measurement of the elapsed time is important to drill down on performance investigations with root-cause analysis. sparkMeasure is a tool and proof-of-concept code that can help you collect and analyze workload metrics of Apache Spark jobs.
You can use sparkMeasure to investigate the performance of Spark workloads both for Scala and Python environments. You can use it from the command-line shell (REPL) or Jupyter notebook or as an aid to instrument your code with custom listeners and metrics reports. It is also possible to use sparkMeasure to collect and store metrics for offline analysis.
The available metrics are collected by extending the Spark listener interface, similarly to what is done by the Spark WebUI. The collected metrics are transformed into Spark DataFrames for ease of analysis.
sparkMeasure allows to collect metrics at the Task level for fine granularity and/or aggregated at Stage level. The collected metrics data come from existing Spark instrumentation. For the case of Spark 2.1.0 this includes execution time, CPU time, time for serialization and deserialization, shuffle read/write time, HDFS I/O metrics and others (see more details in sparkMeasure documentation and code). See also this example analysis of Task Metrics data using a notebook.
In this post you can find some simple examples of how and why to use sparkMeasure to drill down on performance metrics. Ideas for future work in this area include:
- add more examples to illustrate the meaning and accuracy of Spark instrumentation metrics
- show further examples where actionable info or insights can be gained by drilling down into Spark performance metrics
- show limitations of the currently available instrumentation (for example in the area of instrumentation for I/O service time)
- measure the overhead of the instrumentation using Spark listeners
- additional insights that can be derived by examining skew in the distribution of performance metrics at the task level
Acknowledgements
This work has been developed in the context of the CERN Hadoop and Spark service: credits go to my colleagues there for collaboration, in particular to Prasanth Kothuri and Zbigniew Baranowski. Thanks to Viktor Khristenko for direct collaboration on this topic and for his original work on the instrumentation of spark-root with Spark listeners.
Other material that has helped me for the development of this work are Jacek Laskowski's writeup and presentations on the subject of Spark Listeners and the presentation "Making Sense of Spark Performance" by Kay Ousterhout.
The Spark source code and the comments therein have also been very useful for researching this topic. In particular I would like to point to the Scheduler's code for the Spark Listener and the WebUI's JobProgressListener.