Introduction to Apache Spark APIs for Data Processing
This is a self-paced and open introduction course to Apache Spark. Theory and demos cover the main Spark APIs: DataFrame API, Spark SQL, Streaming, Machine Learning. You will also learn how to deploy Spark on CERN computing resources, notably using the CERN SWAN service. Most tutorials and exercises are in Python and run on Jupyter notebooks.
The main course website can be found at https://sparktraining.web.cern.ch/
Apache Spark is a popular engine for data processing at scale. Spark provides an expressive API and a scalable engine that integrates very well with the Hadoop ecosystem as well as with Cloud resources. Spark is currently used by several projects at CERN, notably by IT monitoring, by the security team, by the BE NXCALS project, by teams in ATLAS and CMS. Moreover, Spark is integrated with the CERN Hadoop service, the CERN Cloud service, and the CERN SWAN web notebooks service.
Accompanying notebooks
· Get the notebooks from:
o
https://github.com/cerndb/SparkTraining
o
https://gitlab.cern.ch/db/SparkTraining
· How to run the notebooks:
o
CERN SWAN
(recommended option): ![]()
See
also the SWAN gallery
and the video:
o
Colab ![]() , Binder
, Binder ![]()
o
Your
local/private Jupyter notebook
Course lectures and tutorials
· Introduction and objectives: slides
and video

· Session 1:
Apache Spark fundamentals
o
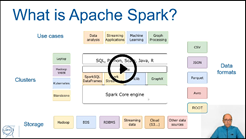
Lecture “Spark architecture and intro to DataFrames”: slides and video
o
Notebooks:
o
Tutorial
on DataFrames with exercises – video ![]()
· Session 2:
Working with Spark DataFrames and SQL
o
Lecture “Introduction to Spark SQL”: slides and video

o
Notebooks:
o
Tutorial
on Spark SQL – video ![]()
· Session 3:
Building on top of the DataFrame API
o
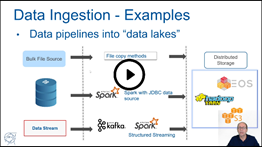
Lecture “Spark as a Data Platform”: slides and video
o
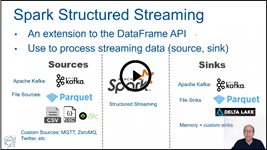
Lecture “Spark Streaming”: slides and video
o
Lecture “Spark and Machine Learning”: slides and video

o
Notebooks:
o
Tutorial on Spark
Streaming – video ![]()
o
Tutorial on Spark
Machine Learning – regression task – video ![]()
o
Tutorial on Spark
Machine Learning – classification task with the Higgs dataset
o
Demo of the Spark
JDBC data source how
to read Oracle tables from Spark
o
Note on Spark
and Parquet format
· Session 4:
How to scale out Spark jobs
o
Lecture “Running Spark on CERN resources”: slides and video

o
Notebooks:
o
Demo on using SWAN
with Spark on Hadoop – video ![]()
o
Demo of Spark
processing Physics data using CERN private Cloud resources – video ![]()
o
Example notebook
for the NXCALS project
·
Bonus
material:
o
How
to monitor Spark execution: slides and video ![]()
o
Spark
as a library, examples of how to use
Spark in Scala and Python programs: code and video ![]()
o
Next
steps: reading
material and links, miscellaneous Spark
notes
·
Read and watch
at your pace:
o
Download the
course material for offline use:
slides.zip,
github_repo.zip,
videos.zip
o
Watch the videos
on YouTube ![]()
Acknowledgements and feedback
Author and contact for
feedback and questions: Luca Canali - Luca.Canali@cern.ch
CERN-IT Spark and data
analytics services
Former contributors: Riccardo
Castellotti, Prasanth Kothuri
Many thanks to CERN Technical
Training for their collaboration and support
License: CC BY-SA 4.0
Published in November 2022
Reposted from https://sparktraining.web.cern.ch/